AWS Media Lab 세미나 후기
- 세미나 후 만들어본 프로그램: StreamSnatcher
- Python 3.9
- GUI:PyQt5
서론
이 글에서는 이번에 다녀온 AWS Media Lab 세미나에 대한 기록을 남겨볼까 합니다. 세미나 후기글이라 일기에 가깝겠지만요. 😂 클라우드 플랫폼사의 세미나인만큼 어떻게 구현되어있나? 보다는 어떻게 사용하는건가?와 퍼포먼스에 대한 강연이었기 때문에 AWS 미디어 서비스를 이용해 스트리밍 애플리케이션을 만드는 방법을 맛만 보고 왔습니다. 😅
워크샵 실습 페이지의 설명이 워낙 잘 되어 있어서 실습 과정을 굳이 따로 서술하진않기로했습니다. 😁
세미나 후 생긴 호기심
세미나에서 스트리밍 서비스가 일정한 세그먼트 크기의 ts파일을 클라이언트에 전송해준다는 말을 들었을 때, 그럼 반대로 ts파일 조각들을 모아 합쳐서 컨버팅하면 스트리밍 웹 서비스에서 동영상을 다운받을 수 있지않을까?하는 생각이 들었습니다. 😂
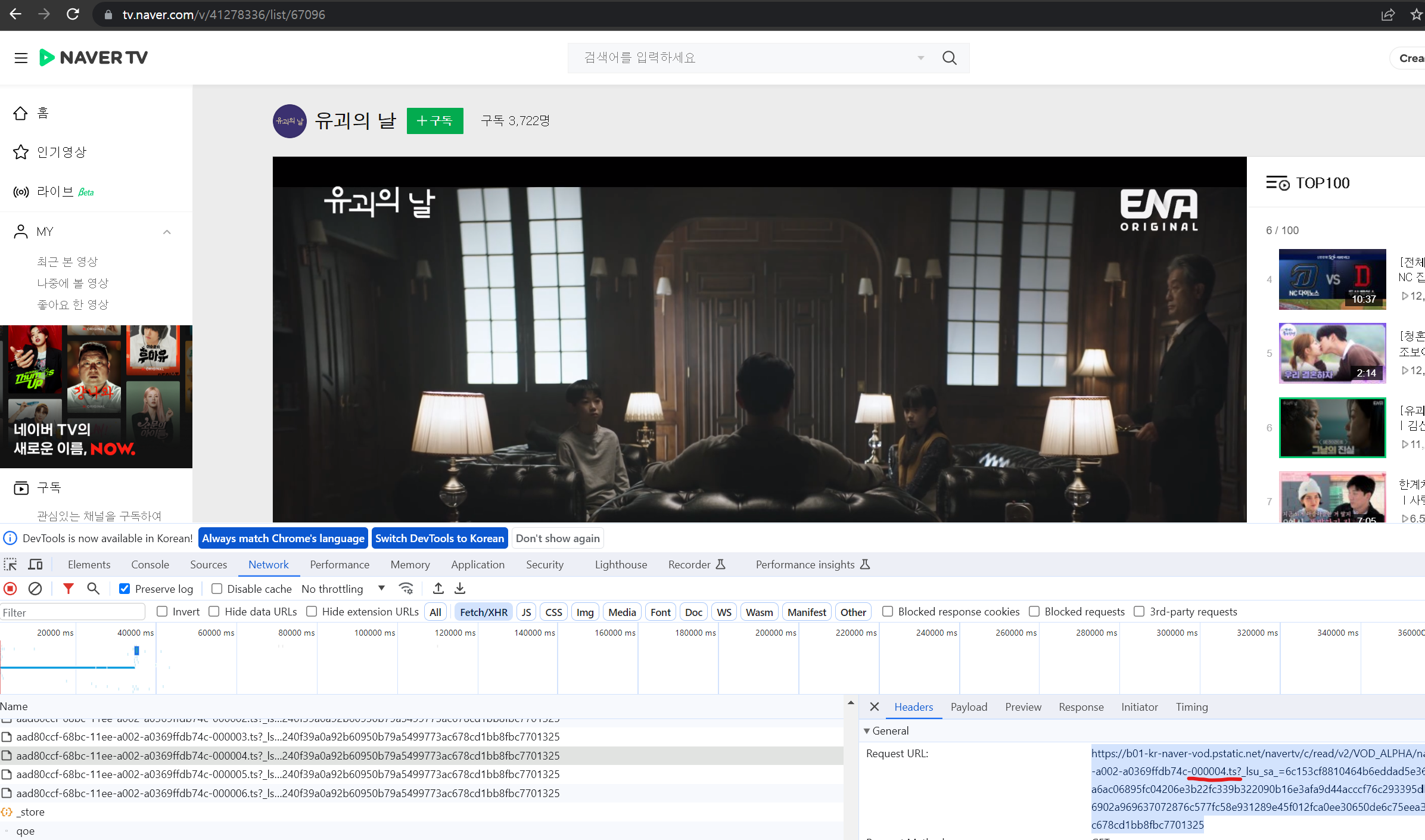
그래서 집으로 돌아와 네이버 TV의 네트워크 패널을 확인해보니 정말 ts파일을 지속적으로 보내주고 있었습니다. curl 명령어를 이용해 한 조각을 다운로드 받아보니 약 5초 정도의 동영상이었습니다.
그 이후 만들어본 것
ts파일은 위 스크린샷처럼 000001.ts, 000002.ts … 연속된 자연수 숫자로 보내고 있기 때문에 동영상 길이와 세그먼트당 영상 길이를 알면 마지막 ts파일의 숫자를 유추할 수 있었습니다. 우선 프로토타입으로 파이썬을 이용해 모든 ts파일을 다운로드 받아서 합친 다음 mp4 확장자로 컨버팅하는 프로그램을 짜봤습니다.
프로토타입 파이썬 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
import aiohttp
import asyncio
import os
import subprocess
import shutil
import re
import sys
def replace_ts_number(url, new_number):
# Regular expression to find .ts file name
pattern = re.compile(r'(\d+)\.ts')
match = pattern.search(url)
# If .ts file name is found, replace the number
if match:
# Format the new number as a zero-padded string
new_number_str = f"{new_number:06}"
old_number = match.group(1)
modified_url = url.replace(f"{old_number}.ts", f"{new_number_str}.ts")
return modified_url
return None # return None if .ts file name is not found
def time_to_seconds(time_str):
# Validate time string format
time_pattern = re.compile(r"^\d+:\d{2}:\d{2}$")
if not time_pattern.match(time_str):
print("Invalid time format! Exiting.")
sys.exit(1)
# Split the time string into hours, minutes, and seconds
hours, minutes, seconds = map(int, time_str.split(':'))
# Convert everything to seconds
return (hours * 3600) + (minutes * 60) + seconds
def get_output_filename():
# Regex pattern to identify invalid filename characters
invalid_chars_pattern = re.compile(r'[\\/:"*?<>|]')
# Get the filename from the user
output_filename = input("Please enter the output filename: ")
# Remove or replace invalid characters
sanitized_filename = re.sub(invalid_chars_pattern, "_", output_filename)
# Ensure the file has the correct extension
if not sanitized_filename.lower().endswith(".mp4"):
sanitized_filename += ".mp4"
return sanitized_filename
def get_config():
url = input("Please enter url: ")
print(f"Url: {url}")
# Get time string from user input & Convert time to seconds
total_seconds = time_to_seconds(input("Please enter the video length (hh:mm:ss): "))
# Display the total time in seconds
print(f"Total video length in seconds: {total_seconds}")
total_segment_length = total_seconds // 4
print(f"Total segment length: {total_segment_length}")
# Use the video ID to set the HEADERS and OUTPUT_FILENAME
headers = {
"Referer": input("Please enter referer: ")
}
# Display the settings
print(f"HEADERS: {headers}")
output_filename = get_output_filename()
print(f"OUTPUT_FILENAME: {output_filename}")
return {
'url': url,
'headers': headers,
'output_filename': output_filename,
'total_segment_length': total_segment_length
}
def concatenate_and_convert(folder_path, output_filename):
# Create a list of all the .ts files
ts_files = sorted([f for f in os.listdir(folder_path) if f.endswith('.ts')])
# Create a list file (contains all .ts files' names)
with open("files.txt", "w") as f:
for ts_file in ts_files:
f.write(f"file '{os.path.join(folder_path, ts_file)}'\n")
# Use ffmpeg to concatenate all .ts files and convert to .mp4
# Note: This assumes ffmpeg is installed and added to PATH
try:
subprocess.run(["ffmpeg", "-f", "concat", "-safe", "0", "-i", "files.txt", "-c", "copy", output_filename],
check=True)
print(f"Conversion complete: {output_filename}")
except subprocess.CalledProcessError as e:
print(f"An error occurred: {str(e)}")
finally:
# Clean up temporary files
os.remove("files.txt")
for ts_file in ts_files:
os.remove(os.path.join(folder_path, ts_file))
# Remove the temporary folder
shutil.rmtree(folder_path)
async def download_file(session, i):
file_name = f"{i:06d}.ts"
file_path = os.path.join("tmp", file_name)
# Skip download if file already exists
if os.path.exists(file_path):
print(f"{file_name} already exists, skipping download.")
return
url = f"{replace_ts_number(config['url'], i)}"
print(f"Request URL: {url}")
async with session.get(url, headers=config['headers']) as response:
if response.status == 200:
with open(file_path, "wb") as f:
f.write(await response.read())
print(f"Success to download {file_name}, status code: {response.status}")
else:
print(f"Failed to download {file_name}, status code: {response.status}")
async def main():
# Ensure the download folder exists
os.makedirs("tmp", exist_ok=True)
conn = aiohttp.TCPConnector(limit=20)
async with aiohttp.ClientSession(connector=conn) as session:
tasks = [download_file(session, i) for i in
range(0, config['total_segment_length'] + 1)]
await asyncio.gather(*tasks)
print("Downloading finished, now converting...")
concatenate_and_convert("tmp", config['output_filename'])
if __name__ == '__main__':
# Get configuration from user input
config = get_config()
# Display the parsed and entered values
print(f"URL: {config['url']}")
print(f"HEADERS: {config['headers']}")
print(f"OUTPUT_FILENAME: {config['output_filename']}")
print(f"TOTAL_SEGMENT_LENGTH: {config['total_segment_length']}")
# Use SelectorEventLoop for Windows
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
# Manage the event loop manually
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
try:
loop.run_until_complete(main())
finally:
loop.close()
프로토타입 코드 실행 결과
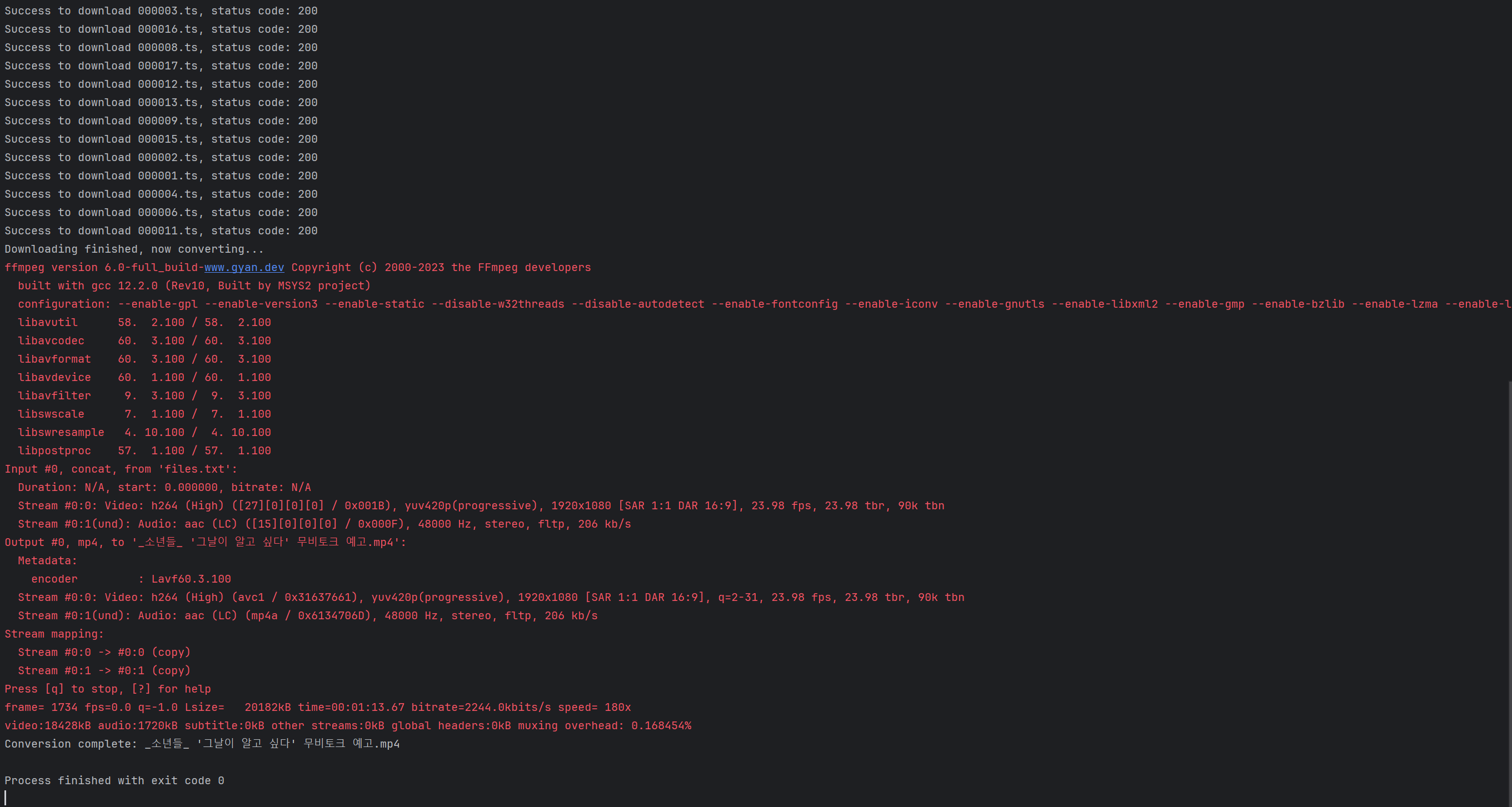
ts파일을 효율적으로 다운로드받기 위해 비동기로 프로그래밍 했습니다. 다운받은 ts파일들을 합치고 mp4파일로 컨버팅하기 위해 subprocess로 외부 프로그램인 ffmpeg를 사용했습니다. 실행시켜보니 원하는대로 동작했습니다. 😆
GUI 붙여보기
이대로 끝내기엔 사용하기도 어렵고 미완성인 상태로 뭔가를 끝내는건 아쉬워서 PyQt5를 이용해 GUI를 붙여보았습니다.

Naver TV 말고도 동작할 수 있도록 범용성을 높히기 위해서 ts파일의 숫자부분을 구분자((*))로 입력할 수 있게 만들었습니다. 또한, 스트리밍 웹서비스마다 zero-padding이 달라서 이 값을 설정할 수 있도록 개선했습니다. 동영상의 전체 세그먼트 수는 직접 입력할 수도 있고, 동영상 길이와 세그먼트당 동영상 길이를 입력하면 자동으로 계산해주도록 했습니다. 다운로드 로직은 프로토타입에서 쓴 코드를 그대로 썼기 때문에 최적화하지 못한 점이 조금 아쉽네요. 😅
AWS 세미나 진짜 후기
하필 저번주부터 독감을 앓고 있었던터라 세미나 당일 몸 상태도 별로 안 좋았고 강의 도중에 급한 회사 업무도 생기는 바람에, 사진 한 장 찍을 생각도 못 한게 너무 아쉽네요… 😭
커피 한 잔 하고 싶은데 한 번도 안 써본 커피머신 때문에 머뭇거리고 있었는데 옆에 커피 마시러 오신 AWS 직원분이 계시길래 여쭤봤더니, 유쾌하게 건성으로 알려주셨어요. 🤣 그 직원분께 좋은 회사에서 일하신다고 부럽다고 말씀드렸더니, 경쟁이 너무 치열하다고 한탄하시더라구요. 😢
강의실 있는 곳 복도에 특이한 디자인의 깊은 의자가 있었는데, 그 안으로 쏙 들어가서 웅크릴 수 있는 디자인이라서 피곤한 날 짧은 시간이라도 휴식을 취하기에 완벽할 것 같더라고요. 회사에 너무너무 가져가고 싶었어요. 😂
무엇보다도, AWS SA로 이직하신 전 팀장님을 뵐 수 있었어요. 사실 이 세미나에 참석한 이유였고요. 😏 강의실이 있는 곳 반대편에는 음료수 만들어주는 로봇도 있었는데 AWS 직원밖에 못 쓴다고 하네요. 전 팀장님께서 파인애플맛 탄산음료 사주셔서 음료수 만드는 로봇을 구경할 수 있었네요. 😁 어쩌다가 들은 이야기로는 로봇 임대료가 월 1000만원이라고 하더라구요. 😱💸
전 팀장님도 뵙고, 재밌는 프로그램을 만드는 계기도 되었으니 정말 유익한 하루였던거 같아요. 😄