파이썬을 이용한 웹 크롤링
들어가기 전…
비동기 프로그래밍과 로깅에 관련된 코드가 포함됨.
크롤러
크롤링(crawling) 혹은 스크레이핑(scraping)은 웹 페이지를 그대로 가져와서 거기서 데이터를 추출해 내는 행위다. 크롤링하는 소프트웨어는 크롤러(crawler)라고 부른다.
내가 크롤링 하려는 것
유로파 유니버셜리스4 라는 게임에 등장하는 국가들의 Flag를 추출해 다운받아볼 것이다.
유로파 유니버셜리스4는 중세시대 말기부터 산업혁명까지 국가를 운영하는 게임인데 꽤 재밌다 ㅎㅎ..
계획
먼저 크롤링을 위해 requests, bs4 라이브러리 설치가 필요하다. requests 말고 파이썬 내장 모듈인 urllib를 써도 되긴하지만 좋은 라이브러리가 있으니까…
1
2
pip install requests
pip install bs4
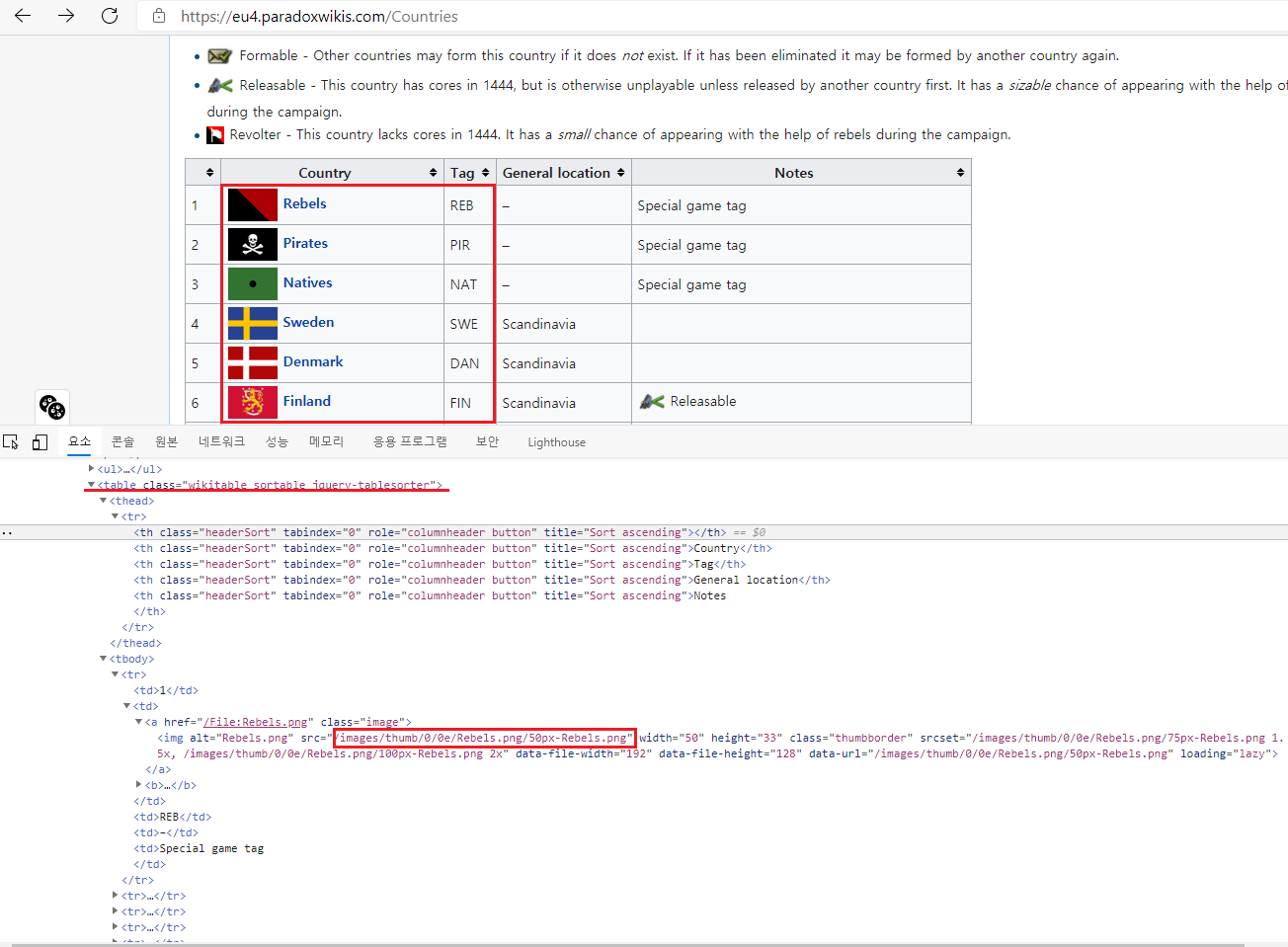 크롤링 목표가 되는 table과 image url이다.
크롤링 목표가 되는 table과 image url이다.
{kind=link}
해당 웹 페이지의 HTML 코드를 긁어서 목표로 하는 Table 요소를 찾아 그 안의 img src 들을 수집해 다운받을 것이다.
코딩
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
from bs4 import BeautifulSoup
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
import requests
import sys
import shutil
import os
import asyncio
import logging
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
FORMAT = "[%(levelname)s][ %(filename)s: %(funcName)s() ] %(message)s"
logging.basicConfig(format=FORMAT, level=logging.INFO)
def get_country_info(with_img_url=False):
try:
req = requests.get('https://eu4.paradoxwikis.com/Countries')
except requests.ConnectionError:
logger.error('wiki connect fail... please check your network.')
sys.exit()
if req.status_code != 200:
logger.error('wiki connect fail... status is not 200.')
sys.exit()
html = req.text
soup = BeautifulSoup(html, 'html.parser')
country_table = soup.find_all(
'table',
{'class': ['wikitable', 'sortable', 'jquery-tablesorter']}
)[0]
trs = country_table.find_all('tr')
tr_tds = trs[1:]
image_src_base = 'https://eu4.paradoxwikis.com'
country_list = []
for tr_td in tr_tds:
tds = tr_td.find_all('td')
_, raw_country_info, raw_country_tag, _, _ = tds
country_name = raw_country_info.find_all('a')[1].text.strip()
country_tag = raw_country_tag.text.strip()
img_src = image_src_base + raw_country_info.a.img.attrs['src']
img_name = img_src.split('/')[-1]
if with_img_url:
country_list.append({
'country_name': country_name,
'country_tag': country_tag,
'img_src': img_src,
'img_name': img_name
})
else:
country_list.append({
'country_name': country_name,
'country_tag': country_tag,
'img_name': img_name
})
return country_list
def image_download(url, path):
if os.path.exists(path):
return
session = requests.Session()
retry = Retry(connect=5, backoff_factor=0.5)
adapter = HTTPAdapter(max_retries=retry)
session.mount('https://', adapter)
response = session.get(url, stream=True)
with open(path, 'wb') as out_file:
shutil.copyfileobj(response.raw, out_file)
del response
logger.info('{} Downloaded'.format(url))
async def async_requester(loop, func, *args):
await loop.run_in_executor(None, func, *args)
def main_code():
country_infos = get_country_info(with_img_url=True)
img_root_dir = 'country_flags/'
if not os.path.isdir(img_root_dir):
os.mkdir(img_root_dir)
logger.info('* Create directory: {}'.format(img_root_dir))
tasks = []
loop = asyncio.get_event_loop()
for country_info in country_infos:
url = country_info['img_src']
path = img_root_dir + country_info['img_name']
tasks.append(async_requester(loop, image_download, url, path))
loop.run_until_complete(asyncio.wait(tasks))
logger.info('* finished!')
if __name__ == '__main__':
main_code()
get_country_info() 함수는 Country 정보가 담긴 Table을 긁어 각 인스턴스의 데이터를 리스트로 정리해준다. with_img_url 매개변수를 이용해 img src url 정보를 가져올지말지 선택할 수 있게 했다.
image_download() 함수는 url과 저장할 경로를 매개변수로 받아 웹상의 이미지 파일을 로컬로 다운받도록 해준다.
async_requester()는 코루틴으로써 비동기적으로 request를 보낼 수 있게 해준다. 만약 동기적으로 대량의 파일을 다운받는다면 상당한 시간이 걸릴 것이다.
1
2
3
4
5
6
7
[INFO][ eu4_contry_flag.py: main_code() ] * Create directory: country_flags/
[INFO][ eu4_contry_flag.py: image_download() ] https://eu4.paradoxwikis.com/images/thumb/4/44/Auvergne.png/50px-Auvergne.png Downloaded
.
.
.
[INFO][ eu4_contry_flag.py: image_download() ] https://eu4.paradoxwikis.com/images/thumb/c/c6/Bengal.png/50px-Bengal.png Downloaded
[INFO][ eu4_contry_flag.py: main_code() ] * finished!
원하는대로 결과물이 나왔다.
후기
크롤러를 만드는 건 꽤 재밌다. 원하는 데이터를 마음껏 뽑을 수 있기 때문이다. 단, 위에서 사용한 방법은 javascript 등으로 동적 랜더링 하는 웹 데이터는 뽑아내지 못한다. 이 경우엔 selenium 라이브러리를 사용해 chromedriver로 동적 크롤링을 해야한다.