Intermediate Machine Learning
목차
- 결측값(Missing value)
- 범주형 변수(Categorical valiables)
- 파이프라인(Piplines)
- 교차검증(Cross validation)
- XGBoost
- 데이터 누수(Data leakage)
결측값(Missing Value)
이 튜토리얼에서는 결측값을 처리하는 세 가지 접근 방식을 배웁니다. 그런 다음 실제 dataset에서 이러한 접근 방식의 효과를 비교합니다.
결측값이 발생할 수 있는 방법에는 여러 가지가 있습니다. 예를 들면,
- 침실이 2개인 집에는 3번째 침실의 크기에 대한 값이 포함되지 않습니다.
- 설문 조사 응답자는 소득을 공유하지 않기로 선택할 수 있습니다.
1
2
3
4
5
6
7
8
y = melbourne_data.Price
melbourne_features = [
'Rooms', 'Distance', 'Postcode', 'Bedroom2', 'Bathroom',
'Car', 'Landsize', 'BuildingArea', 'YearBuilt', 'Lattitude',
'Longtitude', 'Propertycount'
]
X = melbourne_data[melbourne_features]
X.head()
이번에는 결측값이 있는 피쳐도 포함시켰습니다.
대부분의 기계 학습 라이브러리(scikit-learn 포함)는 결측값이 있는 데이터를 사용하여 모델을 빌드하려고 하면 오류가 발생합니다. 따라서 아래 전략 중 하나를 선택해야합니다.
세 가지 접근 방식
결측값을 포함하는 열을 삭제 가장 간단한 방법은 누락 된 값이 있는 열을 삭제하는 것입니다.

이 방법을 사용하면 삭제된 열의 대부분이 누락된 값으로 채워지지 않은 이상, 모델은 많은 정보를 잃게 됩니다. 극단적인 예로 10,000개의 행을 가진 데이터셋에서 하나의 누락된 값이 있었다고 생각해보십시오. 이 방법은 나머지 9,999개의 값까지 통째로 날려버립니다!
결측값 대치(Imputation) 결측값 대치(Imputation)는 누락된 값에 다른 값을 채워넣습니다. 예를 들어, 해당 열의 평균값을 채워넣을 수 있을 것이다.
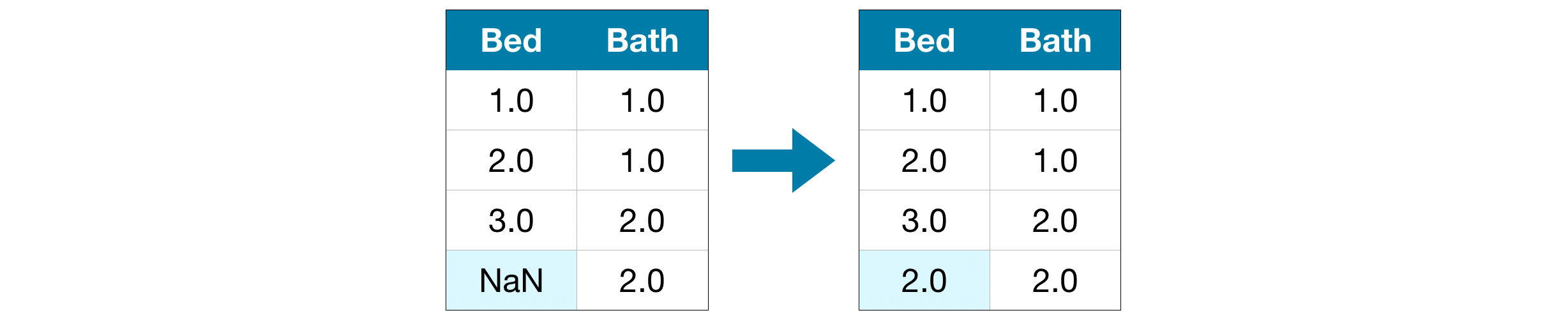
대치 된 값은 대부분의 경우 정확하지 않지만 일반적으로 열을 완전히 삭제하는 것보다 더 정확한 모델로 이어집니다.
확장된 결측값 대치(An Extension To Imputation) 대치는 표준 접근 방식이며 일반적으로 잘 작동합니다. 그러나 대치 된 값은 체계적으로 실제 값보다 높거나 낮을 수 있습니다(dataset에서 수집된 값이 아님). 또는 결측값 대치가 잘 통하지않는 속성일 수도 있습니다. 이 경우 모델은 원래 누락 된 값을 고려하여 더 나은 예측을 할 수 있습니다.
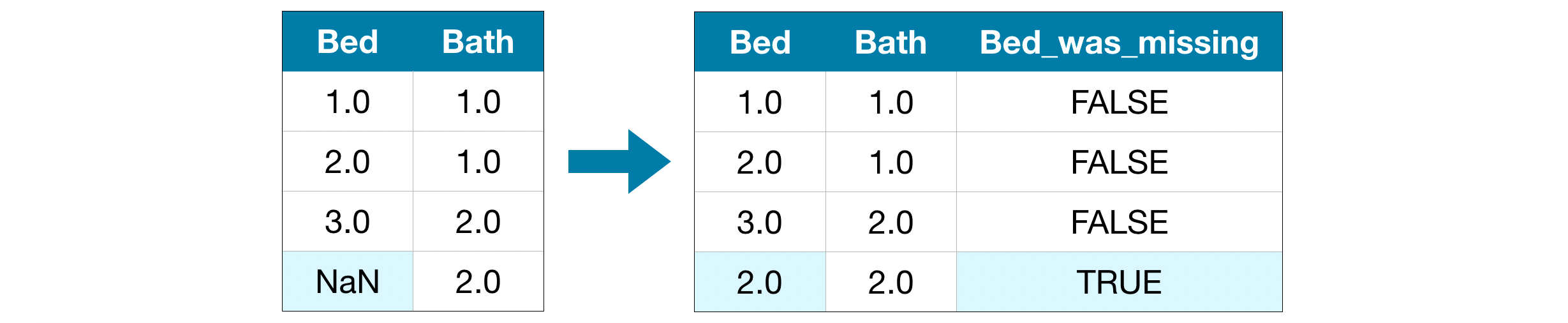
이 접근 방식에서는 이전과 같이 결측값을 대치합니다. 또한 원본 dataset에서 누락 된 항목이 있는 각 열에 대해 대치 된 항목인지 아닌지를 표시하는 새 열을 추가합니다.
이는 더 나은 결과를 얻을 때도 있지만, 전혀 도움이 되지 않을 때도 있습니다.
예시
이 예시에서는 Melbourne Housing dataset으로 작업합니다. 우리 모델은 주택 가격을 예측하기 위해 방의 개수 및 토지 크기와 같은 정보를 사용합니다.
우리는 데이터 로딩 단계에 초점을 맞추지 않을 것입니다. 대신 X_train, X_valid, y_train 및 y_valid에 이미 훈련 및 검증 데이터가 있는 지점에 있다고 가정합시다.
Define Function to Measure Quality of Each Approach 결측값 처리에 대한 다양한 접근 방식을 비교하기 위해 score_dataset() 함수를 정의합니다. 이 함수는 랜덤 포레스트 모델에서 평균 절대 오차(MAE)를 보고합니다.
1
2
3
4
5
6
7
8
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
def score_dataset(train_X, val_X, train_y, val_y):
forest_model = RandomForestRegressor(random_state=1)
forest_model.fit(train_X, train_y)
melb_preds = forest_model.predict(val_X)
return mean_absolute_error(val_y, melb_preds)
Score from Approach 1 (Drop Columns with Missing Values) 우리는 학습 및 유효성 검사 sets를 모두 사용하고 있으므로 두 DataFrame에서 동일한 열을 삭제해야합니다.
1
2
3
4
5
6
7
8
9
10
# Get names of columns with missing values
cols_with_missing = [col for col in X_train.columns
if X_train[col].isnull().any()]
# Drop columns in training and validation data
reduced_X_train = X_train.drop(cols_with_missing, axis=1)
reduced_X_valid = X_valid.drop(cols_with_missing, axis=1)
print("MAE from Approach 1 (Drop columns with missing values):")
print(score_dataset(reduced_X_train, reduced_X_valid, y_train, y_valid))
1
2
MAE from Approach 1 (Drop columns with missing values):
178362.75731037708
Score from Approach 2 (Imputation) 다음으로 SimpleImputer를 사용하여 결측값을 각 열의 평균값으로 대체합니다.
간단하지만 평균 값을 채우는 것은 일반적으로 꽤 잘 수행됩니다(하지만 dataset에 따라 다름). 통계학자는 대치 된 값을 결정하는 더 복잡한 방법(예: 회귀 대치)을 실험했지만 복잡한 전략은 일반적으로 결과를 정교한 기계 학습 모델에 연결하면 추가적인 이점을 제공하지 않습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
from sklearn.impute import SimpleImputer
# Imputation
my_imputer = SimpleImputer()
imputed_X_train = pd.DataFrame(my_imputer.fit_transform(X_train))
imputed_X_valid = pd.DataFrame(my_imputer.transform(X_valid))
# Imputation removed column names; put them back
imputed_X_train.columns = X_train.columns
imputed_X_valid.columns = X_valid.columns
print("MAE from Approach 2 (Imputation):")
print(score_dataset(imputed_X_train, imputed_X_valid, y_train, y_valid))
1
2
MAE from Approach 2 (Imputation):
170777.42401613016
Approach 2가 Approach 1보다 MAE 값이 낮으므로 더 잘 수행됐습니다!
Score from Approach 3 (An Extension to Imputation) 다음으로, 어떤 값이 대치되었는지 추적하면서 누락 된 값을 대치합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# Make copy to avoid changing original data (when imputing)
X_train_plus = X_train.copy()
X_valid_plus = X_valid.copy()
# Make new columns indicating what will be imputed
for col in cols_with_missing:
X_train_plus[col + '_was_missing'] = X_train_plus[col].isnull()
X_valid_plus[col + '_was_missing'] = X_valid_plus[col].isnull()
# Imputation
my_imputer = SimpleImputer()
imputed_X_train_plus = pd.DataFrame(my_imputer.fit_transform(X_train_plus))
imputed_X_valid_plus = pd.DataFrame(my_imputer.transform(X_valid_plus))
# Imputation removed column names; put them back
imputed_X_train_plus.columns = X_train_plus.columns
imputed_X_valid_plus.columns = X_valid_plus.columns
print("MAE from Approach 3 (An Extension to Imputation):")
print(score_dataset(imputed_X_train_plus, imputed_X_valid_plus, y_train, y_valid))
1
2
MAE from Approach 3 (An Extension to Imputation):
170318.51933006055
Approach 3이 Approach 2보다 약간 개선되었습니다.
그렇다면 왜 대치가 열을 삭제하는 것보다 더 나은 성능을 발휘할까요? 학습 데이터에는 10185 개의 행과 12 개의 열이 있으며 3 개의 열에는 결측데이터가 포함됩니다. 각 열에 대해 항목의 절반 미만이 누락되었습니다. 따라서 열을 삭제하면 유용한 정보가 많이 제거되므로 대치가 더 잘 수행 될 것입니다.
1
2
3
4
5
6
# Shape of training data (num_rows, num_columns)
print(X_train.shape)
# Number of missing values in each column of training data
missing_val_count_by_column = (X_train.isnull().sum())
print(missing_val_count_by_column[missing_val_count_by_column > 0])
1
2
3
4
5
(10185, 12)
Car 47
BuildingArea 4843
YearBuilt 4042
dtype: int64
결론
일반적으로 결측값을 대치하면 (Approach 2 및 Approach 3에서) 결 측값이 있는 열을 단순히 삭제했을 때 (Approach 1)에 비해 더 나은 결과를 얻었습니다.
범주형 변수(Categorical Variables)
범주 형 변수는 제한된 수의 값만 사용합니다.
- 아침 식사 빈도를 묻는 설문 조사를 고려하여 “안 함”, “거의”, “대부분의 날”또는 “매일”의 네 가지 옵션을 제공합니다. 이 경우 응답이 고정 된 범주 집합에 속하기 때문에 데이터가 범주형입니다.
- 사람들이 어떤 브랜드의 자동차를 소유하고 있는지에 대한 설문 조사에 응답했다면 응답은 “현대”, “도요타”, “포드”와 같은 카테고리로 분류됩니다. 이 경우의 데이터도 범주형입니다.
이러한 변수를 먼저 사전 처리하지 않고 Python의 대부분의 기계 학습 모델에 연결하려고하면 오류가 발생합니다. 이 튜토리얼에서는 범주형 데이터를 준비하는 데 사용할 수 있는 세 가지 접근 방식을 비교합니다.
세 가지 접근법
- 범주형 변수 삭제 범주형 변수를 처리하는 가장 쉬운 방법은 단순히 dataset에서 제거하는 것입니다. 이 방법은 열에 유용한 정보가 없는 경우에만 잘 작동합니다.
레이블 인코딩(Label Encoding) 레이블 인코딩은 각 고유 값을 다른 정수에 할당합니다.
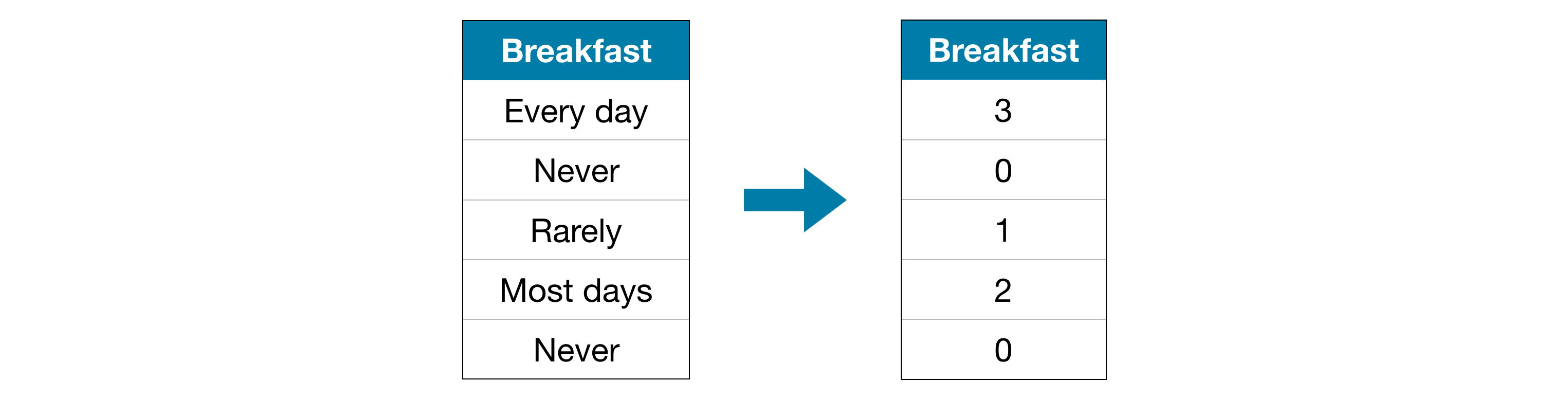
이 접근 방식은 “Never”(0) < “Rarely”(1) < “Most days”(2) < “Every day”(3) 카테고리의 순서를 가정합니다.
이 가정은 범주에 명백한 순위가 있기 때문에, 이 예시에서 의미가 있습니다. 모든 범주형 변수가 값의 순서가 명확한 것은 아니지만 순서형 변수(ordinal variables)로 수행되는 변수를 참조합니다. 트리 기반 모델(예: 의사 결정 트리 및 랜덤 포레스트)의 경우 레이블 인코딩이 순서형 변수와 잘 작동 할 것으로 기대할 수 있습니다.
원-핫 인코딩(One-Hot Encoding) 원-핫 인코딩은 원본 데이터에서 가능한 각 값의 존재 (또는 부재)를 나타내는 새 열을 만듭니다. 이를 이해하기 위해 예제를 살펴 보겠습니다.
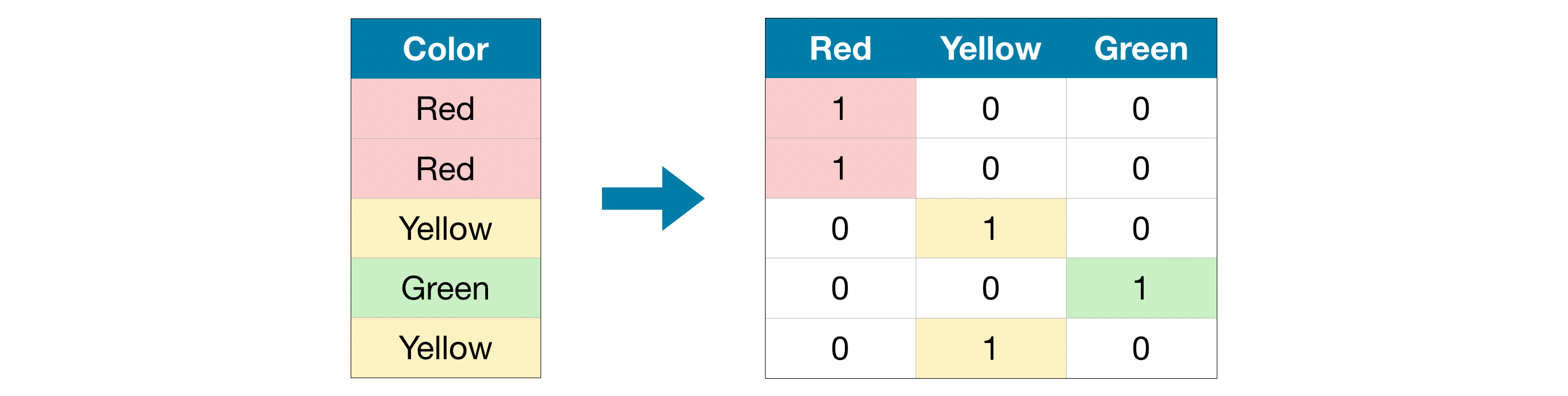
원래 dataset에서 “Color”는 “Red”, “Yellow” 및 “Green”의 세 가지 범주가 있는 범주형 변수입니다. 해당하는 원-핫 인코딩에는 가능한 각 값에 대해 하나의 열과 원래 dataset의 각 행에 대해 하나의 행이 포함됩니다. 원래 값이 “Red”이면 “Red”열에 1을 넣습니다. 원래 값이 “Yellow”이면 “Yellow”열에 1을 넣는 식입니다.
레이블 인코딩과 달리 원-핫 인코딩은 범주의 순서를 가정하지 않습니다. 따라서 범주형 데이터에 명확한 순서가없는 경우, 이 접근 방식이 특히 잘 작동 할 것으로 기대할 수 있습니다 (예 : “Red”는 “Yellow”보다 크거나 작지 않음). 내재 순위가 없는 범주형 변수를 명목 변수(nominal variables)라고합니다.
일반적으로 범주형 변수가 많은 수의 값을 사용하는 경우 원-핫 인코딩이 제대로 수행되지 않습니다(즉, 일반적으로 15개 이상의 서로 다른 값을 갖는 변수에는 사용하지 않음).
예시
아래의 head () 메서드를 사용하여 훈련 데이터를 살펴 봅니다.
1
2
3
4
5
6
7
8
y = melbourne_data.Price
melbourne_features = [
'Type', 'Method', 'Regionname', 'Rooms', 'Distance',
'Postcode', 'Bedroom2', 'Bathroom', 'Landsize', 'Lattitude',
'Longtitude', 'Propertycount'
]
X = melbourne_data[melbourne_features]
X.head()
1
2
3
4
5
6
Type Method Regionname ... Lattitude Longtitude Propertycount
0 h S Northern Metropolitan ... -37.7996 144.9984 4019.0
1 h S Northern Metropolitan ... -37.8079 144.9934 4019.0
2 h SP Northern Metropolitan ... -37.8093 144.9944 4019.0
3 h PI Northern Metropolitan ... -37.7969 144.9969 4019.0
4 h VB Northern Metropolitan ... -37.8072 144.9941 4019.0
다음으로 훈련 데이터의 모든 범주형 변수 목록을 얻습니다.
각 열의 데이터 유형 (또는 dtype)을 확인하여 이를 수행합니다. 객체 dtype은 열에 텍스트가 있음을 나타냅니다(이론적으로는 다른 것이 있을 수 있지만 우리 목적에는 중요하지 않습니다). 이 dataset의 경우, 텍스트가 있는 열은 범주형 변수를 나타냅니다.
1
2
3
4
5
6
# Get list of categorical variables
s = (X_train.dtypes == 'object')
object_cols = list(s[s].index)
print("Categorical variables:")
print(object_cols)
1
2
Categorical variables:
['Type', 'Method', 'Regionname']
Score from Approach 1 (Drop Categorical Variables select_dtypes() 메서드를 사용하여 object인 열을 삭제합니다.
1
2
3
4
5
drop_X_train = X_train.select_dtypes(exclude=['object'])
drop_X_valid = X_valid.select_dtypes(exclude=['object'])
print("MAE from Approach 1 (Drop categorical variables):")
print(score_dataset(drop_X_train, drop_X_valid, y_train, y_valid))
1
2
MAE from Approach 1 (Drop categorical variables):
178362.75731037708
Score from Approach 2 (Label Encoding) Scikit-learn에는 레이블 인코딩을 가져 오는 데 사용할 수 있는 LabelEncoder 클래스가 있습니다. 범주형 변수를 반복하고 레이블 인코더를 각 열에 개별적으로 적용합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from sklearn.preprocessing import LabelEncoder
# Make copy to avoid changing original data
label_X_train = X_train.copy()
label_X_valid = X_valid.copy()
# Apply label encoder to each column with categorical data
label_encoder = LabelEncoder()
for col in object_cols:
label_X_train[col] = label_encoder.fit_transform(X_train[col])
label_X_valid[col] = label_encoder.transform(X_valid[col])
print("MAE from Approach 2 (Label Encoding):")
print(score_dataset(label_X_train, label_X_valid, y_train, y_valid))
1
2
MAE from Approach 2 (Label Encoding):
169840.91485784415
위의 코드 셀에서 각 열에 대해 각 고유 값을 다른 정수에 무작위로 할당합니다. 이는 사용자 지정 레이블을 제공하는 것보다 더 간단한 일반적인 접근 방식입니다. 그러나 모든 순서형 변수에 대해 더 나은 정보를 제공하는 레이블을 제공하면 성능이 추가로 향상 될 수 있습니다.
Score from Approach 3 (One-Hot Encoding) 우리는 scikit-learn의 OneHotEncoder 클래스를 사용하여 원-핫 인코딩을 얻습니다. 동작을 사용자 지정하는 데 사용할 수 있는 여러 매개 변수가 있습니다.
- 검증 데이터에 학습 데이터에 표시되지 않은 클래스가 포함 된 경우 오류를 방지하기 위해 handle_unknown = ‘ignore’를 설정합니다.
- sparse = False를 설정하면 인코딩 된 열이 희소 행렬 대신 numpy 배열로 반환됩니다.
인코더를 사용하기 위해 우리는 원-핫 인코딩을 원하는 범주형 열만 제공합니다. 예를 들어 훈련 데이터를 인코딩하기 위해 X_train[object_cols]를 제공합니다. (아래 코드 셀의 object_cols는 범주형 데이터가 있는 열 이름 목록이므로 X_train[object_cols]에는 training set의 모든 범주형 데이터가 포함됩니다.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from sklearn.preprocessing import OneHotEncoder
# Apply one-hot encoder to each column with categorical data
OH_encoder = OneHotEncoder(handle_unknown='ignore', sparse=False)
OH_cols_train = pd.DataFrame(OH_encoder.fit_transform(X_train[object_cols]))
OH_cols_valid = pd.DataFrame(OH_encoder.transform(X_valid[object_cols]))
# One-hot encoding removed index; put it back
OH_cols_train.index = X_train.index
OH_cols_valid.index = X_valid.index
# Remove categorical columns (will replace with one-hot encoding)
num_X_train = X_train.drop(object_cols, axis=1)
num_X_valid = X_valid.drop(object_cols, axis=1)
# Add one-hot encoded columns to numerical features
OH_X_train = pd.concat([num_X_train, OH_cols_train], axis=1)
OH_X_valid = pd.concat([num_X_valid, OH_cols_valid], axis=1)
print("MAE from Approach 3 (One-Hot Encoding):")
print(score_dataset(OH_X_train, OH_X_valid, y_train, y_valid))
1
2
MAE from Approach 3 (One-Hot Encoding):
169472.8126269023
어떤 접근 방식이 가장 좋습니까?
이 경우 범주형 열(Approach 1)을 삭제하면 MAE 점수가 가장 높았기 때문에 최악의 결과를 얻었습니다. 다른 두 가지 접근 방식의 경우 반환 된 MAE 점수의 가치가 매우 가깝기 때문에 서로간에 의미있는 이점이없는 것으로 보입니다.
일반적으로 원-핫 인코딩(Approach 3)은 일반적으로 최상의 성능을 발휘하고 범주형 열 삭제(Approach 1)는 일반적으로 최악의 성능을 발휘하지만 사례별로 다릅니다.
결론
세상은 범주형 데이터로 가득 차 있습니다. 이 공통 데이터 유형을 사용하는 방법을 안다면 훨씬 더 효과적인 데이터 과학자가 될 것입니다!
파이프라인(Pipelines)
파이프 라인은 데이터 사전 처리 및 모델링 코드를 체계적으로 유지하는 간단한 방법입니다. 특히 파이프 라인은 전처리 및 모델링 단계를 번들로 제공하므로 전체 번들을 마치 단일 단계 인 것처럼 사용할 수 있습니다.
많은 데이터 과학자가 파이프 라인없이 모델을 함께 해킹하지만 파이프 라인에는 몇 가지 중요한 이점이 있습니다. 여기에는 다음이 포함됩니다.
- Cleaner Code 전처리의 각 단계에서 데이터를 계산하는 것은 지저분해질 수 있습니다. 파이프 라인을 사용하면 각 단계에서 학습 및 검증 데이터를 수동으로 추적 할 필요가 없습니다.
- Fewer Bugs 단계를 잘못 적용하거나 전처리 단계를 잊어 버릴 가능성이 적습니다.
- Easier to Productionize 모델을 프로토 타입에서 대규모로 배포 할 수 있는 것으로 전환하는 것은 놀랍도록 어려울 수 있습니다. 여기서 많은 관련 문제를 다루지는 않겠지만 파이프 라인이 도움이 될 수 있습니다.
- More Options for Model Validation 교차검증(Cross validation)을 다루는 다음 튜토리얼에서 예제를 볼 수 있습니다.
예시
1
2
3
4
5
6
7
8
9
y = melbourne_data.Price
melbourne_features = [
'Type', 'Method', 'Regionname', 'Rooms', 'Distance',
'Postcode', 'Bedroom2', 'Bathroom', 'Car', 'Landsize',
'BuildingArea', 'YearBuilt', 'Lattitude', 'Longtitude', 'Propertycount'
]
X = melbourne_data[melbourne_features]
X.describe()
X.head()
1
2
3
4
5
6
7
8
Type Method Regionname ... Lattitude Longtitude Propertycount
0 h S Northern Metropolitan ... -37.7996 144.9984 4019.0
1 h S Northern Metropolitan ... -37.8079 144.9934 4019.0
2 h SP Northern Metropolitan ... -37.8093 144.9944 4019.0
3 h PI Northern Metropolitan ... -37.7969 144.9969 4019.0
4 h VB Northern Metropolitan ... -37.8072 144.9941 4019.0
[5 rows x 15 columns]
세 단계로 전체 파이프 라인을 구성합니다.
Step 1: Define Preprocessing Steps 파이프 라인이 전처리 및 모델링 단계를 함께 묶는 방식과 유사하게 ColumnTransformer 클래스를 사용하여 서로 다른 전처리 단계를 함께 묶습니다.
- 숫자 데이터에서 결측값을 대치합니다.
- 범주형 데이터에 원-핫 인코딩을 적용합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
numerical_cols = X_train.select_dtypes(exclude=['object']).columns
categorical_cols = X_train.drop(numerical_cols, axis=1).columns
# Preprocessing for numerical data
numerical_transformer = SimpleImputer(strategy='constant')
# Preprocessing for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# Bundle preprocessing for numerical and categorical data
preprocessor = ColumnTransformer(
transformers=[
('num', numerical_transformer, numerical_cols),
('cat', categorical_transformer, categorical_cols)
]
)
Step 2: Define the Model 다음으로, 익숙한 RandomForestRegressor 클래스를 사용하여 랜덤 포레스트 모델을 정의합니다.
1
2
3
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=100, random_state=0)
Step 3: Create and Evaluate the Pipeline 마지막으로 Pipeline 클래스를 사용하여 전처리 및 모델링 단계를 번들로 제공하는 파이프 라인을 정의합니다. 주의해야 할 몇 가지 중요한 사항이 있습니다.
- 파이프 라인을 사용하여 학습 데이터를 사전 처리하고 한 줄의 코드로 모델을 맞춥니다.(반대로 파이프 라인이 없으면 대치, 원-핫 인코딩 및 모델 학습을 별도의 단계로 수행해야합니다. 숫자 및 범주형 변수를 모두 처리해야하는 경우 특히 복잡해집니다!)
- 파이프 라인을 사용하면 X_valid의 처리되지 않은 기능을 predict() 명령에 제공하고 파이프 라인은 예측을 생성하기 전에 자동으로 기능을 사전 처리합니다. (그러나 파이프 라인이 없으면 예측하기 전에 유효성 검사 데이터를 사전 처리해야합니다.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from sklearn.metrics import mean_absolute_error
# Bundle preprocessing and modeling code in a pipeline
my_pipeline = Pipeline(steps=[('preprocessor', preprocessor), ('model', model)])
# Preprocessing of training data, fit model
my_pipeline.fit(X_train, y_train)
# Preprocessing of validation data, get predictions
preds = my_pipeline.predict(X_valid)
# Evaluate the model
score = mean_absolute_error(y_valid, preds)
print('MAE:', score)
1
MAE: 163987.3804899362
결론
파이프 라인은 기계 학습 코드를 정리하고 오류를 방지하는 데 유용하며 정교한 데이터 사전 처리가 포함 된 workflows에 특히 유용합니다.
교차검증(Cross validation)
기계 학습은 반복적인 프로세스입니다.
사용할 예측 변수, 사용할 모델 유형, 해당 모델에 제공 할 인수 등에 대한 여러가지 선택에 직면하게됩니다. 지금까지 validation (or hold-out) set를 통해 모델 품질을 측정하여 데이터 중심 방식(data-driven way)으로 이러한 선택을 했습니다.
그러나 이 접근 방식에는 몇 가지 단점이 있습니다. 이를 확인하기 위해 5000개의 행이 있는 dataset가 있다고 가정해봅시다. 일반적으로 데이터의 약 20%를 validation dataset으로 유지하거나 1000 개의 행을 유지합니다. 그러나 이것은 모델 점수를 결정할 때 임의의 기회를 남깁니다. 즉, 모델이 한 set의 1000개 행에서 정확하지 않더라도 다른 set의 1000개 행에서는 잘 수행 될 수도 있습니다.
극단적으로 validation set에 데이터 행이 1개만 있다고 가정해봅시다. 대체 모델을 비교하면 단일 데이터 포인트에서 가장 좋은 예측을하는 모델은 대부분 운이 좋을 것입니다!
일반적으로 validation set가 클수록 모델 품질 측정에 무작위성( “노이즈”라고도 함)이 적고 더 신뢰할 수 있습니다. 불행히도 우리는 training data에서 행을 제거해야만 큰 validation set를 얻을 수 있으며, training datasets가 작을수록 모델이 더 나빠집니다!
교차검증(Cross validation)이란?
교차 검증Cross validation)에서는 여러 데이터 하위 집합에서 모델링 프로세스를 실행하여 여러 모델 품질 측정 값을 얻습니다.
예를 들어, 데이터를 전체 dataset의 20%씩 5개로 나누는 것으로 시작할 수 있습니다. 이 경우 데이터를 5개의 “폴드(folds)”로 나눴다고합니다.
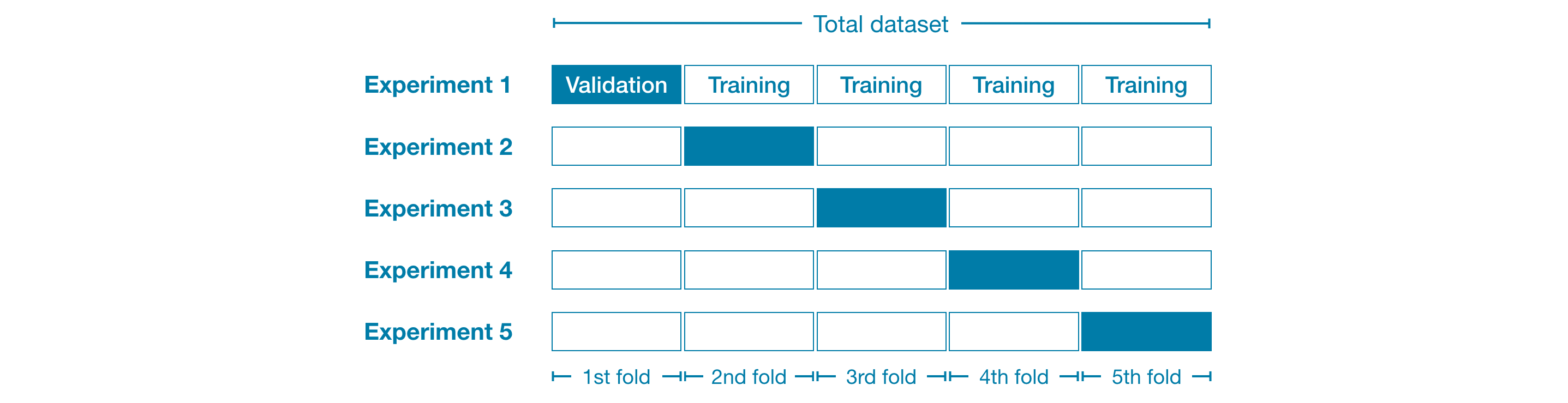
그런 다음 각 fold에 대해 하나의 실험을 실행합니다.
- Experiment 1에서는 첫 번째 fold를 validation (또는 hold-out) set로 사용하고 나머지는 모두 학습 데이터로 사용합니다. 이를 통해 20% hold-out set를 기반으로 모델 품질 측정 값을 얻을 수 있습니다.
- Experiment 2에서는 두 번째 fold의 데이터를 보관하고 두 번째 fold를 제외한 모든 항목을 모델 학습에 사용합니다. 그런 다음 hold-out set를 사용하여 모델 품질의 두 번째 추정치를 얻습니다.
- 모든 fold를 hold-out set로 한 번 사용하여 이 프로세스를 반복합니다. 이를 종합하면 데이터의 100%가 어느 시점에서 hold-out으로 사용되고 모든 행을 동시에 사용하지 않더라도 dataset의 모든 행을 기반으로하는 모델 품질 측정 값이됩니다.
교차 검증은 언제 사용해야할까요?
교차 검증은 모델 품질에 대해 보다 정확한 측정을 제공하며 이는 많은 모델링 결정을 내리는 경우 특히 중요합니다. 그러나 여러 모델 (fold마다 하나씩)을 추정하기 때문에 실행하는 데 더 오래 걸릴 수 있습니다.
그렇다면 이러한 장단점을 고려할 때 각 접근 방식을 언제 사용해야합니까?
- 추가적인 컴퓨팅 자원 부담이 크지 않은 소규모 dataset의 경우 교차 유효성 검사를 실행해야합니다.
- 더 큰 dataset의 경우 단일 validation set로 충분합니다. 코드가 더 빠르게 실행되고 hold-out을 위해 일부를 재사용 할 필요가 거의 없는 충분한 데이터가 있을 수 있습니다.
큰 dataset와 작은 dataset를 구성하는 것에 대한 단순한 임계 값은 없습니다. 그러나 모델을 실행하는 데 몇 분 이하가 소요되는 경우 교차 검증으로 전환하는 것이 좋습니다.
또는 교차 검증을 실행하고 각 실험의 점수가 비슷해 보이는지 확인할 수 있습니다. 각 실험에서 동일한 결과가 나오면 단일 validation set로 충분할 것입니다.
예시
파이프 라인없이 교차 유효성 검사를 수행 할 수 있지만 매우 어렵습니다! 파이프 라인을 사용하면 코드가 매우 간단해집니다.
scikit-learn에서 cross_val_score() 함수를 사용하여 교차 검증 점수를 얻습니다. cv 매개 변수로 fold의 수를 설정합니다.
1
2
3
4
5
from sklearn.model_selection import cross_val_score
# Multiply by -1 since sklearn calculates *negative* MAE
scores = -1 * cross_val_score(my_pipeline, X, y, cv=5, scoring='neg_mean_absolute_error')
print("MAE scores:\n", scores)
1
2
3
MAE scores:
[207273.036228 195544.72890525 186907.59467108 152084.99219493
158236.49133232]
scoring 매개 변수는 보고 할 모델 품질의 척도를 선택합니다.이 경우에는 음의 평균 오차(negative mean absolute error, MAE)를 선택했습니다. scikit-learn에 대한 문서는 옵션 목록을 보여줍니다.
일반적으로 대체 모델을 비교하기 위해 단일 모델 품질 측정 값을 원합니다. 그래서 우리는 Experiments에서 평균을 취합니다.
1
2
print("Average MAE score (across experiments):")
print(scores.mean())
1
2
Average MAE score (across experiments):
180009.368666316
결론
교차 검증을 사용하면 코드를 정리하는 추가 이점과 함께 모델 품질을 훨씬 더 잘 측정 할 수 있습니다. 더 이상 별도의 훈련 및 검증 데이터를 구분할 필요가 없습니다. 따라서 특히 작은 dataset의 경우 좋은 개선입니다!
XGBoost
이 튜토리얼에서는 그라디언트 부스팅으로 모델을 구축하고 최적화하는 방법을 배웁니다. 이 방법은 많은 Kaggle 대회를 지배하고 다양한 데이터 세트에서 최첨단 결과를 달성합니다.
이 과정의 대부분에서는 여러 의사 결정 트리의 예측을 평균화하여 단일 의사 결정 트리보다 더 나은 성능을 달성하는 랜덤 포레스트 방법을 사용하여 예측했습니다.
랜덤 포레스트 방법을 “앙상블 기법(ensemble methods)”이라고합니다. 정의에 따라 앙상블 기법은 여러 모델의 예측을 결합합니다 (예 : 랜덤 포레스트의 경우 여러 트리).
다음으로 그라디언트 부스팅이라는 또 다른 앙상블 방법에 대해 알아 봅니다.
Gradient Boosting
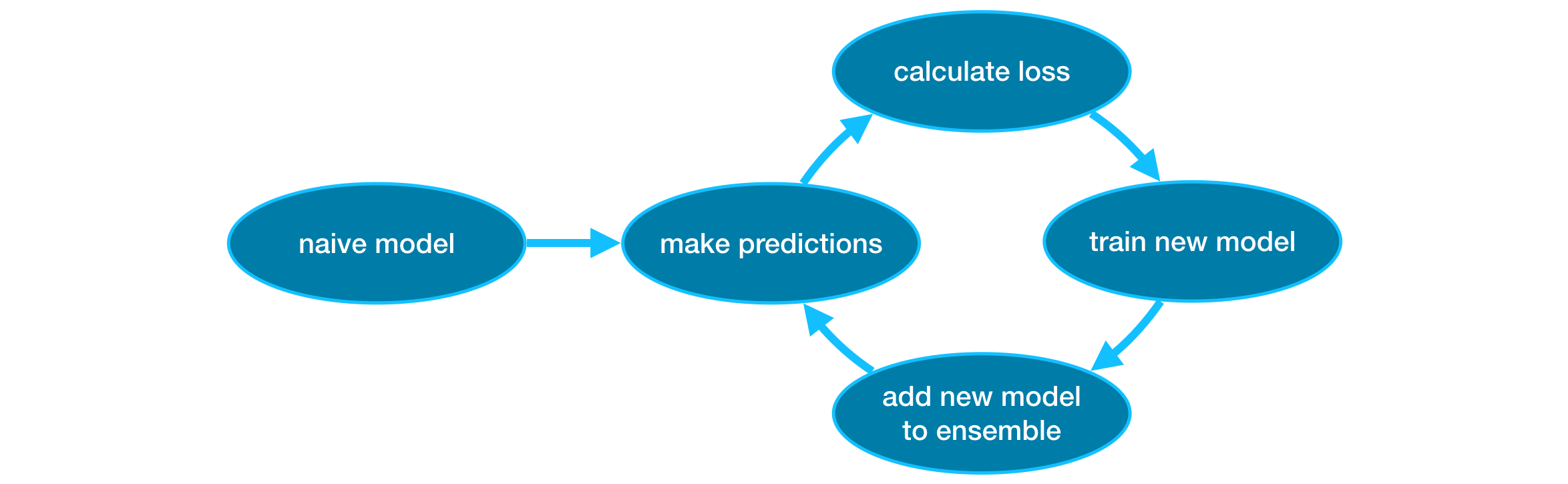
Gradient boosting은 반복적으로 모델을 앙상블에 추가하기 위해주기를 거치는 방법입니다.
이는 예측이 매우 나이브 할 수 있는 단일 모델로 앙상블을 초기화하는 것으로 시작됩니다. (예측이 매우 정확하지 않더라도 앙상블에 추가하면 이러한 오류가 해결됩니다.)
사이클은 아래와 같습니다.
- 먼저 현재 앙상블을 사용하여 dataset의 각 observation에 대한 predictions을 생성합니다. predictions을 수행하기 위해 앙상블의 모든 모델에서 predictions을 추가합니다.
- 이러한 predictions은 손실 함수(loss function)를 계산하는 데 사용됩니다(예: 평균 제곱 오차(Mean squared error)).
- 그런 다음 손실 함수를 사용하여 앙상블에 추가 할 새 모델을 맞춥니 다. 특히, 이 새로운 모델을 앙상블에 추가하면 손실을 줄일 수 있도록 모델 매개 변수를 결정합니다. (참고: “Gradient boosting”의 “Gradient”는 손실 함수에서 경사하강법(Gradient descent)을 사용하여, 이 새 모델에서 매개 변수를 결정한다는 사실을 나타냅니다.)
- 마지막으로 앙상블에 새 모델을 추가합니다.
- 위 과정을 반복합니다.
예시
이 예제에서는 XGBoost 라이브러리로 작업합니다. XGBoost는 성능과 속도에 초점을 맞춘 몇 가지 추가 기능과 함께 Gradient Boosting을 구현 한 eXtreme Gradient Boosting의 약자입니다. (Scikit-learn에는 다른 버전의 Gradient Boosting이 있지만 XGBoost에는 몇 가지 기술적 이점이 있습니다.)
다음 코드 셀에서는 XGBoost(xgboost.XGBRegressor) 용 scikit-learn API를 가져옵니다. 이를 통해 scikit-learn에서와 마찬가지로 모델을 구축하고 맞출 수 있습니다. 출력에서 볼 수 있듯이 XGBRegressor 클래스에는 많은 조정 가능한 매개 변수가 있습니다. 곧 이에 대해 알게 될 것입니다!
1
2
3
4
from xgboost import XGBRegressor
my_model = XGBRegressor()
my_model.fit(X_train, y_train)
예측을 하고 모델을 평가합니다.
1
2
3
4
from sklearn.metrics import mean_absolute_error
predictions = my_model.predict(X_valid)
print("Mean Absolute Error: " + str(mean_absolute_error(predictions, y_valid)))
1
Mean Absolute Error: 239960.14714193667
Parameter Tuning
XGBoost에는 정확도와 훈련 속도에 큰 영향을 미칠 수있는 몇 가지 매개 변수가 있습니다. 이해해야 할 첫 번째 매개 변수는 다음과 같습니다.
n_estimators n_estimators는 위에서 설명한 모델링주기를 통과 할 횟수를 지정합니다. 앙상블에 포함 된 모델 수와 같습니다.
- 값이 너무 낮으면 과소적합이 발생하여 학습 데이터와 테스트 데이터 모두에 대한 예측이 부정확하게됩니다.
- 값이 너무 높으면 과적합이 발생하여 훈련 데이터에 대한 정확한 예측이 이루어지지만 테스트 데이터에 대한 예측은 정확하지 않을 수 있습니다.
일반적인 값의 범위는 100-1000이지만 아래에서 설명하는 learning_rate 매개 변수에 따라 크게 달라집니다.
앙상블에서 모델 수를 설정하는 코드는 다음과 같습니다.
1
2
my_model = XGBRegressor(n_estimators=500)
my_model.fit(X_train, y_train)
early_stopping_rounds early_stopping_rounds는 n_estimators에 대한 이상적인 값을 자동으로 찾는 방법을 제공합니다. early_stopping_rounds는 n_estimators 값에 따른 유효성 검사 점수 개선이 멈추면 여러분이 hard stop 하지 않아도 모델의 반복을 중지하도록합니다. 높은 n_estimators 값을 설정 한 다음 early_stopping_rounds를 사용하여 반복을 중지 할 최적의 시간을 찾는 것이 현명합니다.
무작위 확률로 인해 유효성 검사 점수가 향상되지 않는 단일 라운드가 발생하기 때문에 중지하기 전에 허용 할 연속 열화 라운드 수를 지정해야합니다. early_stopping_rounds = 5 설정은 합리적인 선택입니다. 이 경우, 우리는 검증 점수가 악화되는 5회 연속 후에 중지합니다.
early_stopping_rounds를 사용할 때 유효성 검사 점수를 계산하기 위해 일부 데이터를 따로 설정해야합니다.이 작업은 eval_set 매개 변수를 설정하여 수행됩니다.
early stopping을 포함하도록 위의 예를 수정할 수 있습니다.
1
2
3
4
5
6
7
my_model = XGBRegressor(n_estimators=500)
my_model.fit(
X_train, y_train,
early_stopping_rounds=5,
val_set=[(X_valid, y_valid)],
verbose=False
)
나중에 모든 데이터로 모델을 맞추려면 조기 중지로 실행할 때 최적이라고 판단한 값으로 n_estimators를 설정하십시오.
learning_rate 각 구성 요소 모델의 예측을 단순히 더하여 예측을 얻는 대신 추가하기 전에 각 모델의 예측에 작은 수(learning rate이라고 함)를 곱할 수 있습니다.
이것은 우리가 앙상블에 추가하는 각 트리가 덜 유용하다는 것을 의미합니다. 따라서 과적합 없이 n_estimators에 대해 더 높은 값을 설정할 수 있습니다. early stopping을 사용하면 적절한 수의 트리가 자동으로 결정됩니다.
일반적으로 learning rate가 낮고 estimators가 많을수록 더 정확한 XGBoost 모델이 생성되지만, 더 많은 반복을 수행하기 때문에 모델을 학습하는 데 더 오래 걸립니다. 기본적으로 XGBoost는 learning_rate=0.1을 설정합니다.
위의 예를 수정하여 learning rate를 변경하면 다음 코드가 생성됩니다.
1
2
3
4
5
6
7
my_model = XGBRegressor(n_estimators=1000, learning_rate=0.05)
my_model.fit(
X_train, y_train,
early_stopping_rounds=5,
eval_set=[(X_valid, y_valid)],
verbose=False
)
n_jobs 런타임이 고려되는 대규모 dataset에서는 병렬 처리를 사용하여 모델을 더 빠르게 빌드 할 수 있습니다. 머신의 코어 수와 동일한 n_jobs 매개 변수를 설정하는 것이 일반적입니다. 작은 dataset에서는 도움이되지 않습니다.
결과 모델은 더 나아지지 않을 것이므로 피팅 시간에 대한 미세 최적화는 일반적으로 주의를 분산시킬뿐입니다. 그러나 적합 명령을 수행하는 동안 대기하는 데 오랜 시간이 소요되는 대규모 dataset에서 유용합니다.
다음은 수정 된 예입니다.
1
2
3
4
5
6
7
my_model = XGBRegressor(n_estimators=1000, learning_rate=0.05, n_jobs=4)
my_model.fit(
X_train, y_train,
early_stopping_rounds=5,
eval_set=[(X_valid, y_valid)],
verbose=False
)
결론
XGBoost는 표준 테이블 형식 데이터(Pandas DataFrames에 저장하는 데이터 유형, 이미지 및 비디오와 같은, 보다 이국적인 유형의 데이터) 작업을 위한 선도적 인 소프트웨어 라이브러리입니다. 신중한 매개 변수 조정을 통해 매우 정확한 모델을 훈련 할 수 있습니다.
데이터 누수(Data leakage)
이 튜토리얼에서는 데이터 누수(Data leakage)는 무엇이며 이를 방지하는 방법을 배웁니다. 이를 방지하는 방법을 모르면 누수가 자주 발생하고 미묘하고 위험한 방식으로 모델을 망칠 것입니다. 따라서 이것은 데이터 과학자를 실습하기위한 가장 중요한 개념 중 하나입니다.
데이터 누수(Data leakage)는 학습 데이터에 대상에 대한 정보가 포함되어있을 때 발생하지만 예측에 모델을 사용할 때는 유사한 데이터를 사용할 수 없습니다. 이로 인해 모델은 training set 또는 validation data에서 높은 성능이 발생하지만 프로덕션에서 성능이 저하됩니다.
즉, leakage로 인해 모델에 대한 의사 결정을 시작할 때까지 모델이 정확해 보이지만 사실은 매우 부정확해집니다.
leakage에는 target leakage와 train-test contamination라는 두 가지 주요 유형이 있습니다.
Target leakage Target leakage는 예측시 사용할 수 없는 데이터가 예측 변수에 포함된 경우 발생합니다. 단순히 기능이 좋은 예측을 하는 데 도움이 되는지 여부뿐만 아니라 데이터를 사용할 수 있게 되는 시기 또는 시간순으로 대상 누출에 대해 생각하는 것이 중요합니다.
아래 예시가 도움이 될 것입니다. 누가 폐렴에 걸릴지 예측하고 싶다고 상상해보세요. 원시 데이터의 맨 위 몇 행은 다음과 같습니다.
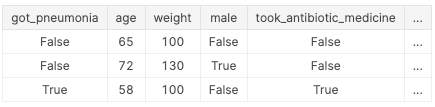
사람들은 회복을 위해 폐렴에 걸린 후 항생제를 복용합니다. 원시 데이터는 이러한 열 간의 강한 관계를 보여 주지만 got_pneumonia의 값이 결정된 후 took_antibiotic_medicine이 자주 변경됩니다. 이것이 target leakage입니다.
이 모델은 took_antibiotic_medicine에 대해 False 값을 가진 사람은 폐렴이 없다는 것을 알 수 있습니다. 유효성 검사 데이터는 학습 데이터와 동일한 소스에서 제공되므로 패턴은 유효성 검사에서 반복되며 모델은 훌륭한 유효성 검사 (또는 교차 유효성 검사) 점수를 갖게됩니다.
그러나 폐렴에 걸릴 환자조차도 미래의 건강에 대한 예측이 필요할 때 아직 항생제를 투여받지 못했기 때문에 모델이 나중에 현실 세계에 배포 될 때 매우 부정확 할 것입니다.
이러한 유형의 데이터 누수를 방지하려면 목표 값이 실현 된 후 업데이트 (또는 생성) 된 모든 변수를 제외해야합니다.

Train-Test Contamination training data와 validation data를 구분하지 않으면 다른 유형의 leakage가 발생합니다.
유효성 검사는 모델이 이전에 고려하지 않은 데이터에 대해 수행하는 방식을 측정하는 것임을 기억하셔야합니다. validation data가 전처리 동작에 영향을 미치는 경우, 이 프로세스를 미묘하게 손상시킬 수 있습니다. 이를 Train-Test Contamination 이라고도합니다.
예를 들어 train_test_split()을 호출하기 전에 전처리(결측값에 대한 imputer fitting 등)를 실행한다고 가정 해보십시오. 최종 결과는? 모델은 좋은 유효성 검사 점수를 얻어서 큰 신뢰를 얻을 수 있지만 결정을 내리기 위해 배포 할 때는 성능이 떨어집니다.
결국, validation 또는 test data의 데이터를 predictions에 통합 했으므로 새 데이터로 일반화 할 수없는 경우에도 특정 데이터에 대해 잘 수행 될 수 있습니다. 이 문제는 더 복잡한 피처(feature) 엔지니어링을 수행 할 때 더욱 미묘하고 위험해집니다.
검증이 간단한 훈련-테스트 분할을 기반으로하는 경우 전처리 단계의 fitting을 포함하여 모든 유형의 fitting에서 validation data를 제외합니다. scikit-learn 파이프 라인을 사용하면 더 쉽습니다. 교차 유효성 검사를 사용할 때 파이프 라인 내에서 사전 처리를 수행하는 것이 훨씬 더 중요합니다!
예시
이 예시에서는 target leakage를 감지하고 제거하는 방법을 한 가지 배웁니다.
신용 카드 응용 프로그램에 대한 dataset을 사용하고 기본 데이터 설정 코드는 건너 뜁니다. 최종 결과는 각 신용 카드 응용 프로그램에 대한 정보가 DataFrame X에 저장됩니다. 우리는 이를 사용하여 Series y에서 어떤 응용 프로그램이 수락되었는지 예측할 것입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import pandas as pd
# Read the data
data = pd.read_csv(
'input_data/AER_credit_card_data.csv',
true_values = ['yes'],
false_values = ['no']
)
# Select target
y = data.card
# Select predictors
X = data.drop(['card'], axis=1)
print("Number of rows in the dataset:", X.shape[0])
X.head()
1
2
3
4
5
6
7
8
9
Number of rows in the dataset: 1319
reports age income share ... dependents months majorcards active
0 0 37.66667 4.5200 0.033270 ... 3 54 1 12
1 0 33.25000 2.4200 0.005217 ... 3 34 1 13
2 0 33.66667 4.5000 0.004156 ... 4 58 1 5
3 0 30.50000 2.5400 0.065214 ... 0 25 1 7
4 0 32.16667 9.7867 0.067051 ... 2 64 1 5
[5 rows x 11 columns]
dataset이 작기 때문에 모델 품질의 정확한 측정을 보장하기 위해 교차 검증을 사용할 것입니다.
1
2
3
4
5
6
7
8
9
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
# Since there is no preprocessing, we don't need a pipeline (used anyway as best practice!)
my_pipeline = make_pipeline(RandomForestClassifier(n_estimators=100))
cv_scores = cross_val_score(my_pipeline, X, y, cv=5,scoring='accuracy')
print("Cross-validation accuracy: %f" % cv_scores.mean())
1
Cross-validation accuracy: 0.980292
With experience, you’ll find that it’s very rare to find models that are accurate 98% of the time. It happens, but it’s uncommon enough that we should inspect the data more closely for target leakage.
다음은 데이터 탭에서도 확인할 수있는 데이터 요약입니다.
- card: 1 if credit card application accepted, 0 if not
- reports: Number of major derogatory reports
- age: Age n years plus twelfths of a year
- income: Yearly income (divided by 10,000)
- share: Ratio of monthly credit card expenditure to yearly income
- expenditure: Average monthly credit card expenditure
- owner: 1 if owns home, 0 if rents
- selfempl: 1 if self-employed, 0 if not
- dependents: 1 + number of dependents
- months: Months living at current address
- majorcards: Number of major credit cards held
- active: Number of active credit accounts
몇 가지 변수가 의심스러워 보입니다. For example, does expenditure mean expenditure on this card or on cards used before appying?
이 시점에서 기본 데이터 비교가 매우 유용 할 수 있습니다.
1
2
3
4
5
6
7
expenditures_cardholders = X.expenditure[y]
expenditures_noncardholders = X.expenditure[~y]
print('Fraction of those who did not receive a card and had no expenditures: %.2f' \
%((expenditures_noncardholders == 0).mean()))
print('Fraction of those who received a card and had no expenditures: %.2f' \
%(( expenditures_cardholders == 0).mean()))
1
2
Fraction of those who did not receive a card and had no expenditures: 1.00
Fraction of those who received a card and had no expenditures: 0.02
위와 같이 카드를 받지 못한 사람은 지출이 없었고, 카드를 받은 사람 중에 지출이 없는 사람은 오직 2%에 불과했습니다. 우리 모델의 정확도가 높은 것은 놀라운 일이 아닙니다. 그러나 이것은 또한 지출이 그들이 신청 한 카드에 대한 지출을 의미하는 target leakage의 경우로 보입니다.
share 역시, expenditure에 의해 부분적으로 결정되기 때문에 제외되어야합니다. active와 majorcards 변수는 다소 명확하지 않지만 설명에서 볼 때 관련이 있습니다. 대부분의 상황에서 더 많은 정보를 찾기 위해 데이터를 만든 사람을 추적 할 수 없다면 신중한 할 필요가 있습니다.
다음과 같이 target leakage 없이 모델을 실행합니다.
1
2
3
4
5
6
7
8
# Drop leaky predictors from dataset
potential_leaks = ['expenditure', 'share', 'active', 'majorcards']
X2 = X.drop(potential_leaks, axis=1)
# Evaluate the model with leaky predictors removed
cv_scores = cross_val_score(my_pipeline, X2, y, cv=5, scoring='accuracy')
print("Cross-val accuracy: %f" % cv_scores.mean())
1
Cross-val accuracy: 0.834704
이 정확도는 상당히 낮아 실망스러울 수 있습니다. 그러나 우리가 새 응용 프로그램에서 사용할 때, leakage 모델은 교차 검증에서 더 높은 점수를 냈음에도 불구하고 지금(80% 정확도 기대치)보다 훨씬 더 나쁠 것입니다.
결론
Data leakage는 많은 데이터 과학 애플리케이션에서 수백만 달러를 손해볼 수 있는 실수가 될 수 있습니다. 훈련 및 검증 데이터를 신중하게 분리하면 train-test contamination을 방지 할 수 있으며 파이프 라인은 이러한 분리를 구현하는 데 도움이 될 수 있습니다. 마찬가지로 주의, 상식 및 데이터 탐색의 조합은 target leakage을 식별하는 데 도움이 될 수 있습니다.