Natural Language Processing
데이터는 타임 스탬프, 센서 판독값, 이미지, 범주형 레이블 등 다양한 형태로 제공됩니다. 그러나 텍스트는 사용 방법을 아는 사람들에게 여전히 가장 귀중한 데이터입니다.
자연어 처리(NLP)에 대한 이 과정에서는 최고의 NLP 라이브러리인 spaCy를 사용하여 텍스트 작업에서 가장 중요한 작업을 수행합니다.
마지막으로 다음 용도로 spaCy를 사용할 수 있습니다.
- 기본 텍스트 처리 및 패턴 일치
- 텍스트로 기계 학습 모델 구축
- 단어와 문서의 의미를 수치적으로 포착하는 단어 임베딩(word embeddings)으로 텍스트 표현
이 과정을 최대한 활용하려면 기계 학습에 대한 경험이 필요합니다. scikit-learn에 대한 경험이 없다면 Intro to Machine Learning 및 Intermediate Machine Learning을 먼저 학습해주세요.
목차
- NLP with spaCy
- Tokenizing
- Text preprocessing
- Pattern Matching
- Text Classification
- Word Vectors(Word Embeddings)
NLP with spaCy
spaCy는 NLP를 위한 선도적인 라이브러리이며 빠르게 가장 인기있는 Python 프레임워크 중 하나가 되었습니다. 쉽게 직관적이고 훌륭한 문서를 찾아볼 수 있습니다.
spaCy는 언어별로 다르며 크기가 다른 모델에 의존합니다. spacy.load를 사용하여 spaCy 모델을 로드 할 수 있습니다.
- spacy 설치하기
1
2
3
```shell
conda install spacy
```
- en 모델 설치하기
1
2
3
```shell
spacy download en
```
예를 들어, 다음은 영어 모델을 로드하는 방법입니다.
1
2
3
import spacy
nlp = spacy.load('en_core_web_sm')
모델이로드 되면 다음과 같이 텍스트를 처리 할 수 있습니다.
1
doc = nlp("Tea is healthy and calming, don't you think?")
이렇게 만든 doc 객체로 할 수 있는 일이 많습니다.
Tokenizing
토큰이 포함 된 dictionary 객체를 반환합니다. 토큰은 개별 단어 및 구두점과 같은 문서의 텍스트 단위입니다. SpaCy는 “don’t”와 같은 축약을 “do”와 “n’t”의 두 개의 토큰으로 나눕니다. 반복문을 이용해 토큰을 볼 수 있습니다.
1
2
for token in doc:
print(token)
1
2
3
4
5
6
7
8
9
10
11
Tea
is
healthy
and
calming
,
do
n't
you
think
?
dictionary를 반복하면 토큰 객체가 제공됩니다. 이러한 각 토큰에는 추가 정보가 함께 제공됩니다. 대부분의 경우 중요한 것은 token.lemma_ 및 token.is_stop입니다.
Text preprocessing
단어로 모델링하는 방법을 개선하기위한 몇 가지 유형의 전처리가 있습니다. 첫 번째는 “lemmatizing”입니다. 단어의 “기본형”은 기본 형식입니다. 예를 들어, “walk”는 “walking”이라는 단어의 기본형입니다. 따라서 “walking”라는 단어를 lemmatize하면 “walk”로 변환합니다.
불용어를 제거하는 것도 일반적입니다. 불용어는 해당 언어에서 자주 발생하며 많은 정보를 포함하지 않는 단어입니다. 영어 불용어에는 “the”, “is”, “and”, “but”, “not”이 포함됩니다.
spaCy 토큰을 사용하면 token.lemma_는 기본형을 반환하고 token.is_stop은 토큰이 불용어이면 True를 반환하고 그렇지 않으면 False를 반환합니다.
1
2
3
4
print(f"Token \t\tLemma \t\tStopword".format('Token', 'Lemma', 'Stopword'))
print("-"*40)
for token in doc:
print(f"{str(token)}\t\t{token.lemma_}\t\t{token.is_stop}")
1
2
3
4
5
6
7
8
9
10
11
12
13
Token Lemma Stopword
----------------------------------------
Tea tea False
is be True
healthy healthy False
and and True
calming calming False
, , False
do do True
n't n't True
you you True
think think False
? ? False
기본형과 불용어 식별이 중요한 이유는 무엇일까요? 언어 데이터에는 유익한 데이터와 혼합된 많은 노이즈가 있습니다. 위 문장에서 중요한 단어는 tea, healthy, calming입니다. 불용어를 제거하면 예측 모델이 관련 단어에 집중하는 데 도움이 될 수 있습니다. 동일한 단어의 여러 형태를 하나의 기본 형태로 결합함으로써 유사하게 표제화하는 것이 도움이됩니다(“calming”, “calms”, “calmed”는 모두 “calm”으로 변경됩니다).
그러나 불용어를 lemmatizing하고 삭제하면 모델 성능이 저하 될 수 있습니다. 따라서 이 전처리를 하이퍼 파라미터 최적화 프로세스의 일부로 취급해야합니다.
Pattern Matching
또 다른 일반적인 NLP 작업은 텍스트의 청크(chunks) 또는 전체 문서 내에서 토큰 또는 구문을 매칭시키는 것입니다. 정규식으로도 패턴 매칭을 수행 할 수 있지만 spaCy의 매칭 기능이 더 사용하기 쉽습니다.
개별 토큰을 매칭 시키려면 Matcher를 만듭니다. term 목록을 매칭 시키려면 PhraseMatcher를 사용하는 것이 더 쉽고 효율적입니다. 예를 들어 일부 텍스트에서 다양한 스마트 폰 모델이 표시되는 위치를 찾으려면 관심있는 모델 이름에 대한 패턴을 만들 수 있습니다. 먼저 PhraseMatcher 자체를 만듭니다.
1
2
from spacy.matcher import PhraseMatcher
matcher = PhraseMatcher(nlp.vocab, attr='LOWER')
matcher는 모델의 단어(vocabulary)를 사용하여 생성됩니다. 여기에서는 이전에 로드 한 작은 영어 모델을 사용합니다. attr=’LOWER’를 설정하면 소문자 텍스트의 구문과 매칭합니다. 이것은 대소 문자를 구분하지 않는 매칭을 제공합니다.
다음으로 텍스트에서 매칭시킬 용어(term) 목록을 만듭니다. 구문 매칭에는 문서(document) 객체로서의 패턴이 필요합니다. 이를 얻는 가장 쉬운 방법은 nlp 모델을 사용하는 것입니다.
1
2
3
terms = ['Galaxy Note', 'iPhone 11', 'iPhone XS', 'Google Pixel']
patterns = [nlp(text) for text in terms]
matcher.add("TerminologyList", patterns)
그런 다음 텍스트에서 document를 만들어 검색하고 구문 matcher를 사용하여 텍스트에서 term이 나오는 위치를 찾습니다.
1
2
3
4
5
6
# Borrowed from https://daringfireball.net/linked/2019/09/21/patel-11-pro
text_doc = nlp("Glowing review overall, and some really interesting side-by-side "
"photography tests pitting the iPhone 11 Pro against the "
"Galaxy Note 10 Plus and last year’s iPhone XS and Google Pixel 3.")
matches = matcher(text_doc)
print(matches)
1
[(3766102292120407359, 17, 19), (3766102292120407359, 22, 24), (3766102292120407359, 30, 32), (3766102292120407359, 33, 35)]
여기서 매칭되는 항목은 match ID의 tuple과 구의 시작과 끝의 위치입니다.
1
2
match_id, start, end = matches[0]
print(nlp.vocab.strings[match_id], text_doc[start:end])
1
TerminologyList iPhone 11
Text Classification
Text Classification with SpaCy
NLP의 일반적인 작업은 텍스트 분류입니다. 이것은 기존의 기계 학습 의미에서의 “분류”이며 텍스트에 적용됩니다. 예를 들어 스팸 감지, 감정 분석 및 고객 쿼리 태그 지정이 있습니다.
분류기(classifier)는 대부분의 이메일 클라이언트에서 공통적인 기능인 스팸 메시지를 감지합니다. 다음은 사용할 데이터에 대한 개요입니다.
1
2
3
4
5
6
import pandas as pd
# Loading the spam data
# ham is the label for non-spam messages
spam = pd.read_csv('input_data/spam.csv')
spam.head(10)
1
2
3
4
5
6
7
8
9
10
11
label text
0 ham Go until jurong point, crazy.. Available only ...
1 ham Ok lar... Joking wif u oni...
2 spam Free entry in 2 a wkly comp to win FA Cup fina...
3 ham U dun say so early hor... U c already then say...
4 ham Nah I don't think he goes to usf, he lives aro...
5 spam FreeMsg Hey there darling it's been 3 week's n...
6 ham Even my brother is not like to speak with me. ...
7 ham As per your request 'Melle Melle (Oru Minnamin...
8 spam WINNER!! As a valued network customer you have...
9 spam Had your mobile 11 months or more? U R entitle...
Bag of Words
기계 학습 모델은 원시 텍스트 데이터에서 학습하지 않습니다. 즉, 텍스트를 숫자로 변환해야합니다.
가장 간단한 일반적인 표현은 원-핫 인코딩의 변형입니다. 각 document를 vocabulary의 각 term에 대한 사용 빈도에 따른 벡터로 나타냅니다. vocabulary는 document의 모음인 말뭉치(corpus)의 모든 토큰(terms)에서 구성됩니다.
예를 들어, “Tea is life. Tea is love.” “Tea is healthy, calming, and delicious.”가 corpus라면, 그러면 vocabulary는 {“tea”, “is”, “life”, “love”, “healthy”, “calming”, “and”, “delicious”}(구두점 무시)입니다.
각 문서에 대해 term이 발생하는 횟수를 세고 해당 계수를 벡터의 적절한 요소에 배치합니다. 첫 번째 문장은 “tea”를 두 번 가지고 있고 그것은 vocabulary의 첫 번째 위치입니다. 그래서 우리는 벡터의 첫 번째 요소에 숫자 2를 넣습니다. 벡터로서의 문장은 다음과 같습니다.
1
2
𝑣1 = [22110000]
𝑣2 = [11001111]
이것을 Bag of Words이라고합니다. 유사한 term을 가진 document는 유사한 벡터를 가지고 있음을 알 수 있습니다. Vocabulary에는 종종 수만 개의 용어가 있으므로 이러한 벡터는 매우 커질 수 있습니다.
또 다른 일반적인 표현은 TF-IDF(Term Frequency-Inverse Document Frequency)입니다. TF-IDF는 각 term의 개수가 corpus에서 term의 빈도에 따라 조정된다는 점을 제외하면 bag of words와 유사합니다. TF-IDF를 사용하면 잠재적으로 모델을 개선 할 수 있습니다. 해당 내용은 여기에서는 다루지 않습니다.
Building a Bag of Words model
bag of words에 document가 있으면 이러한 벡터를 모든 기계 학습 모델에 대한 입력으로 사용할 수 있습니다. spaCy는 bag of words 변환을 처리하고 TextCategorizer 클래스를 사용하여 간단한 선형 모델(linear model)을 구축합니다.
TextCategorizer는 spaCy 파이프(pipe)입니다. 파이프는 토큰을 처리하고 변환하기위한 클래스입니다. nlp=spacy.load(‘encore_web_sm’)을 사용하여 spaCy 모델을 생성 할 때 음성 태깅, 엔티티 인식 및 기타 변환의 일부를 수행하는 기본 파이프가 있습니다. 모델 doc=nlp( “Some text here”)를 통해 텍스트를 실행하면 파이프의 출력이 doc 객체의 토큰에 첨부됩니다. token.lemma의 기본형은 이 파이프 중 하나에서 나옵니다.
모델에 파이프를 제거하거나 추가 할 수 있습니다. 여기서 할 일은 파이프없이 빈 모델을 만드는 것입니다(모든 모델에는 항상 tokenizer가 있으므로 tokenizer는 제외). 그런 다음 TextCategorizer 파이프를 만들어 빈 모델에 추가합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# Create an empty model
from spacy.lang.en import English
nlp = English()
# Create the TextCategorizer with exclusive classes and "bow" architecture
# https://spacy.io/api/language#create_pipe
# https://spacy.io/api/architectures#TextCatBOW
nlp.create_pipe(
"textcat",
config={
'model': {
'@architectures': 'spacy.TextCatBOW.v1',
'exclusive_classes': True,
'ngram_size': 1,
'no_output_layer': False
}
}
)
textcat = nlp.add_pipe('textcat')
클래스가 ham 또는 spam이므로 “exclusive_classes”를 True로 설정합니다. 또한 bag of words(“bow”) 아키텍처로 구성했습니다. spaCy는 CNN(convolutional neural network) 아키텍처도 제공하지만 현재 필요한 것보다 더 복잡합니다.
다음으로 모델에 레이블을 추가합니다. 여기서 “ham”은 실제 메시지를, “spam”은 스팸 메시지입니다.
1
2
3
# Add labels to text classifier
textcat.add_label("ham")
textcat.add_label("spam")
Training a Text Categorizer Model
다음으로 데이터의 레이블을 TextCategorizer에 필요한 형식으로 변환합니다. 각 문서에 대해 각 클래스에 대한 boolean 값의 dictionary를 만듭니다.
예를 들어 텍스트가 “ham”이면 사전 {‘ham’: True, ‘spam’: False}이 필요합니다. 모델은 ‘cats’ key가 있는 다른 dictionary 내에서 이러한 레이블을 찾고 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
train_data = []
for item in spam.iloc:
doc = nlp.make_doc(item.text)
example = Example.from_dict(
doc,
{
'cats': {
'ham': item.label == 'ham',
'spam': item.label == 'spam'
}
}
)
train_data.append(example)
이제 모델을 훈련 할 준비가 되었습니다. 먼저 nlp.begin_training()을 사용하여 최적화 프로그램을 만듭니다. spaCy는이 최적화 프로그램을 사용하여 모델을 업데이트합니다. 일반적으로 모델을 작은 배치(batch)로 훈련하는 것이 더 효율적입니다. spaCy는 훈련을 위해 미니 배치(minibatch)를 생성하는 생성기를 반환하는 미니 배치 함수를 제공합니다. 마지막으로 미니 배치는 텍스트와 레이블로 분할 된 다음 nlp.update와 함께 사용되어 모델의 매개 변수를 업데이트합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
random.seed(1)
spacy.util.fix_random_seed(1)
optimizer = nlp.begin_training()
# Iterate through minibatches
# https://spacy.io/api/language#update
losses = {}
for epoch in range(10):
random.shuffle(train_data)
# Create the batch generator with batch size = 8
batches = minibatch(train_data, size=8)
# Iterate through minibatches
for batch in batches:
nlp.update(batch, sgd=optimizer, losses=losses)
print(losses)
1
2
3
4
5
6
7
8
9
10
{'textcat': 0.5549327614952294}
{'textcat': 0.6942927120308386}
{'textcat': 0.7603908179353354}
{'textcat': 0.7798789901942472}
{'textcat': 0.8150759574802218}
{'textcat': 0.8868370061354872}
{'textcat': 0.9019728956993387}
{'textcat': 0.9116310472891854}
{'textcat': 0.9546235444465657}
{'textcat': 0.9629162331118234}
Making Predictions
이제 학습 된 모델이 있으므로 predict() 메서드를 사용하여 예측할 수 있습니다. 입력 텍스트는 nlp.tokenizer로 토큰화해야합니다. 그런 다음 점수를 반환하는 predict 메서드에 토큰을 전달합니다. 점수는 입력 텍스트가 클래스에 속할 확률입니다.
1
2
3
4
5
6
7
8
9
texts = ["Are you ready for the tea party????? It's gonna be wild",
"URGENT Reply to this message for GUARANTEED FREE TEA" ]
docs = [nlp.make_doc(text) for text in texts]
# Use textcat to get the scores for each doc
textcat = nlp.get_pipe('textcat')
scores = textcat.predict(docs)
scores
1
2
array([[9.9998641e-01, 1.3548736e-05],
[3.4928420e-03, 9.9650711e-01]], dtype=float32)
점수는 확률이 가장 높은 레이블을 선택하여 단일 클래스 또는 레이블을 예측하는 데 사용됩니다. scores.argmax로 가장 높은 확률의 인덱스를 얻은 다음 인덱스를 사용하여 textcat.labels에서 레이블 문자열을 가져옵니다.
1
2
3
# From the scores, find the label with the highest score/probability
predicted_labels = scores.argmax(axis=1)
[textcat.labels[label] for label in predicted_labels]
1
['ham', 'spam']
모델을 평가하는 것은 일단 예측이 이루어지면 간단합니다. 정확도를 측정하려면 일부 테스트 데이터에 대해 올바른 예측이 몇 개 이루어 졌는지 계산하고 총 예측 수로 나눈 값입니다.
Word Vectors(Word Embeddings)
이 시점에서 텍스트에 대한 기계 학습은 먼저 텍스트를 숫자로 표현해야한다는 것을 알고 있습니다. 지금까지 bag of words 표현으로 이 작업을 수행했습니다. 그러나 일반적으로 단어 임베딩으로 더 잘할 수 있습니다.
단어 임베딩(단어 벡터라고도 함)은 벡터가 해당 단어가 사용되는 방식 또는 의미에 해당하는 방식으로 각 단어를 숫자로 나타냅니다. 벡터 인코딩은 단어가 나타나는 컨텍스트를 고려하여 학습됩니다. 유사한 문맥에 나타나는 단어는 유사한 벡터를 갖습니다. 예를 들어, “표범”, “사자” 및 “호랑이”에 대한 벡터는 서로 가깝지만 “행성”과 “성”은 멀리 떨어져 있습니다.
더 멋진 단어 사이의 관계는 수학 연산으로 조사 할 수 있습니다. “man”과 “woman”에 대한 벡터를 빼면 다른 벡터가 반환됩니다. “king”에 대한 벡터에 추가하면 결과는 “queen”에 대한 벡터에 가깝습니다.
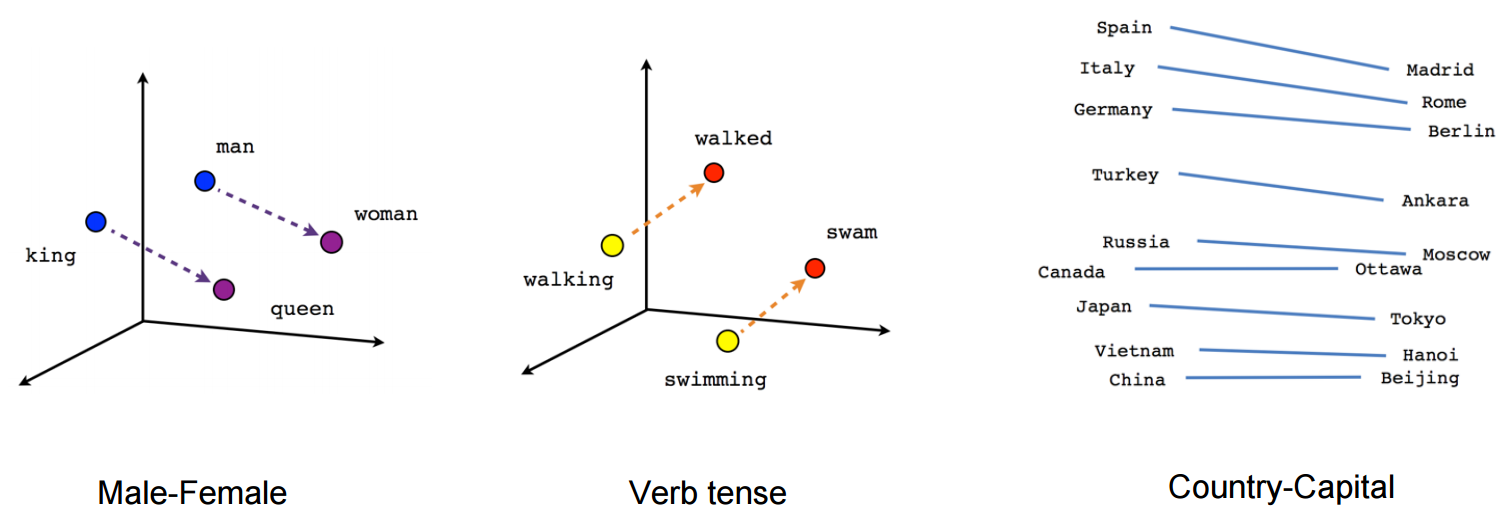
이러한 벡터는 기계 학습 모델의 피쳐로 사용할 수 있습니다. 단어 벡터는 일반적으로 bag of words 인코딩 위의 모델 성능을 향상시킵니다. spaCy는 Word2Vec이라는 모델에서 학습한 임베딩을 제공합니다. en_core_web_lg와 같은 대규모 언어 모델을 로드하여 액세스 할 수 있습니다. 그런 다음 .vector 속성의 토큰에서 사용할 수 있습니다.
1
2
3
4
5
import numpy as np
import spacy
# Need to load the large model to get the vectors
nlp = spacy.load('en_core_web_lg')
1
2
3
4
# Disabling other pipes because we don't need them and it'll speed up this part a bit
text = "These vectors can be used as features for machine learning models."
with nlp.disable_pipes():
vectors = np.array([token.vector for token in nlp(text)])
1
vectors.shape
1
(12, 300)
이것은 각 단어에 대해 하나의 벡터가 있는 300차원 벡터입니다. 그러나 우리는 문서 수준(document-level) 레이블만 가지고 있으며 모델은 단어 수준(word-level) 임베딩을 사용할 수 없습니다. 따라서 전체 문서에 대한 벡터 표현이 필요합니다.
모든 단어 벡터를 모델 학습에 사용할 수 있는 단일 문서 벡터로 결합하는 방법에는 여러 가지가 있습니다. 간단하고 놀랍도록 효과적인 방법은 단순히 문서의 각 단어에 대한 벡터를 평균화하는 것입니다. 그런 다음 이러한 문서 벡터를 모델링에 사용할 수 있습니다.
spaCy는 doc.vector로 얻을 수 있는 평균 문서 벡터를 계산합니다. 다음은 스팸 데이터를 로드하고 문서 벡터로 변환하는 예입니다.
1
2
3
4
5
6
7
8
9
10
import pandas as pd
# Loading the spam data
# ham is the label for non-spam messages
spam = pd.read_csv('../input/nlp-course/spam.csv')
with nlp.disable_pipes():
doc_vectors = np.array([nlp(text).vector for text in spam.text])
doc_vectors.shape
1
(5572, 300)
Classification Models
문서 벡터를 사용하면 scikit-learn 모델, xgboost 모델 또는 다른 모델링에 대한 기타 표준 접근 방식을 학습 할 수 있습니다.
1
2
3
4
5
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
doc_vectors, spam.label, test_size=0.1, random_state=1
)
다음은 SVM(Support Vector Machine)을 사용하는 예입니다. Scikit-learn은 SVM 분류기인 LinearSVC를 제공합니다. 이것은 다른 scikit-learn 모델과 유사하게 작동합니다.
1
2
3
4
5
6
from sklearn.svm import LinearSVC
# Set dual=False to speed up training, and it's not needed
svc = LinearSVC(random_state=1, dual=False, max_iter=10000)
svc.fit(X_train, y_train)
print(f"Accuracy: {svc.score(X_test, y_test) * 100:.3f}%", )
1
Accuracy: 97.849%
Document Similarity
콘텐츠가 유사한 문서는 일반적으로 유사한 벡터를 가지고 있습니다. 따라서 벡터 간의 유사성을 측정하여 유사한 문서를 찾을 수 있습니다. 이것에 대한 일반적인 메트릭은 두 벡터 𝐚와 𝐛 사이의 각도를 측정하는 코사인 유사성입니다.
1
cos𝜃 = 𝐚⋅𝐛 / ‖𝐚‖ ‖𝐛‖
이것은 𝐚과 𝐛의 내적을 각 벡터의 크기로 나눈 값입니다. 코사인 유사성은 -1과 1 사이에서 달라질 수 있으며, 각각 완전 유사성과 완전히 반대입니다. 이를 계산하려면 scikit-learn의 메트릭을 사용하거나 자체 함수를 작성할 수 있습니다.
1
2
def cosine_similarity(a, b):
return a.dot(b)/np.sqrt(a.dot(a) * b.dot(b))
1
2
3
a = nlp("REPLY NOW FOR FREE TEA").vector
b = nlp("According to legend, Emperor Shen Nung discovered tea when leaves from a wild tree blew into his pot of boiling water.").vector
cosine_similarity(a, b)
1
0.7030031