Pandas
목차
- Creating, Reading and Writing
- Indexing, Selecting & Assigning
- Summary Functions and Maps
- Grouping and Sorting
- Data Types and Missing Values
- Renaming and Combining
Creating, Reading and Writing
이 튜토리얼에서는 이미 존재하는 데이터로 작업하는 방법과 함께 고유한 데이터를 만드는 방법을 배웁니다.
pandas 라이브러리를 사용하기 위해 다음과 같이 import 해줍니다.
1
import pandas as pd
Creating data
Pandas에는 DataFrame과 Series라는 두 가지 핵심 개체가 있습니다.
DataFrame DataFrame은 테이블입니다. 여기에는 개별 항목의 배열이 포함되며 각 항목에는 특정 값이 있습니다. 각 항목은 행(또는 레코드)과 열에 해당합니다.
1
pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]})
1
2
3
Yes No
0 50 131
1 21 2
위 예시에서 “0, No”항목의 값은 131입니다. “0, Yes”항목의 값은 50입니다.
1
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], 'Sue': ['Pretty good.', 'Bland.']})
1
2
3
Bob Sue
0 I liked it. Pretty good.
1 It was awful. Bland.
DataFrame 항목은 정수로 제한되지 않습니다.
우리는 이러한 DataFrame 객체를 생성하기 위해 pd.DataFrame() 생성자를 사용하고 있습니다. 새로운 것을 선언하는 구문은 키가 열 이름(이 예시에서는 Bob, Sue)이고 값이 항목 목록인 사전입니다. 이것은 새로운 DataFrame을 구성하는 표준적인 방법이며 앞으로 가장 많이 접하게 될 것입니다.
사전 목록 생성자는 열 레이블에 값을 할당하지만 행 레이블에 대해 0(0, 1, 2, 3, …)부터 오름차순 개수만 사용합니다. 상관없을수도 있지만, 우리는 이러한 레이블을 직접 할당하고 싶을 때도 있을겁니다.
DataFrame에서 사용되는 행 레이블 목록을 인덱스(Index)라고합니다. 생성자에서 index 매개 변수를 사용하여 값을 할당 할 수 있습니다.
1
2
3
4
5
6
7
pd.DataFrame(
{
'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']
},
index=['Product A', 'Product B']
)
1
2
3
Bob Sue
Product A I liked it. Pretty good.
Product B It was awful. Bland.
Series 대조적으로 Series는 일련의 데이터 값입니다. DataFrame이 테이블이면 Series는 목록입니다.
1
pd.Series([1, 2, 3, 4, 5])
1
2
3
4
5
6
0 1
1 2
2 3
3 4
4 5
dtype: int64
Series는 본질적으로 DataFrame의 단일 열입니다. 따라서 DataFrame처럼 index 매개 변수를 사용하여 Series에 열 값을 할당 할 수 있습니다. 그러나 시리즈에는 열 이름이 없고 하나의 전체 이름만 있습니다.
1
pd.Series([30, 35, 40], index=['2015 Sales', '2016 Sales', '2017 Sales'], name='Product A')
1
2
3
4
2015 Sales 30
2016 Sales 35
2017 Sales 40
Name: Product A, dtype: int64
Series와 DataFrame은 밀접하게 관련되어 있습니다. DataFrame을 실제로 “함께 묶인” Series로 생각하면 도움이됩니다.
Reading data files
DataFrame 또는 Series를 직접 만들 수 있으면 편리합니다. 그러나 대부분의 경우 실제로 직접 데이터를 직접 생성하지는 않습니다. 대신 이미 존재하는 데이터로 작업 할 것입니다.
데이터는 다양한 모양과 포멧으로 저장할 수 있습니다. 가장 기본적인 것은 csv 파일입니다. csv 파일을 열면 다음과 같은 결과가 나타납니다.
1
2
3
4
Product A,Product B,Product C,
30,21,9,
35,34,1,
41,11,11
csv 파일은 쉼표로 구분 된 값 테이블입니다. 이제 dataset를 따로 설정하고 DataFrame으로 읽을 때 실제 dataset가 어떻게 보이는지 살펴 보겠습니다. pd.read_csv() 함수를 사용하여 데이터를 DataFrame으로 읽어들입니다.
1
wine_reviews = pd.read_csv("input_data/winemag-data-130k-v2.csv")
shape 속성을 사용하여 결과 DataFrame의 크기를 확인할 수 있습니다.
1
wine_reviews.shape
1
(129971, 14)
따라서 새로운 DataFrame에는 14개의 다른 열로 분할 된 약 130,000개의 레코드가 있습니다. 거의 2백만 개의 항목입니다!
처음 5개 행을 가져 오는 head() 명령을 사용하여 결과 DataFrame의 내용을 검사 할 수 있습니다.
1
wine_reviews.head()
1
2
3
4
5
6
7
8
Unnamed: 0 country ... variety winery
0 0 Italy ... White Blend Nicosia
1 1 Portugal ... Portuguese Red Quinta dos Avidagos
2 2 US ... Pinot Gris Rainstorm
3 3 US ... Riesling St. Julian
4 4 US ... Pinot Noir Sweet Cheeks
[5 rows x 14 columns]
pd.read_csv() 함수는 사용자가 30개 이상의 선택적 매개 변수와 함께 사용할 수 있습니다. 예를 들어 이 dataset에는 csv 파일에 기본 제공 index가 있지만 pandas가 자동으로 인식하지 못 했습니다. 이 때, pandas가 index로 해당 열을 사용하도록 만들기 위해 index_col을 지정할 수 있습니다.
1
2
wine_reviews = pd.read_csv("input_data/winemag-data-130k-v2.csv", index_col=0)
wine_reviews.head()
1
2
3
4
5
6
7
8
country ... winery
0 Italy ... Nicosia
1 Portugal ... Quinta dos Avidagos
2 US ... Rainstorm
3 US ... St. Julian
4 US ... Sweet Cheeks
[5 rows x 13 columns]
Indexing, Selecting & Assigning
Native accessors
네이티브 Python 개체는 데이터를 인덱싱하는 좋은 방법을 제공합니다. Pandas는 이 모든 것을 전달하므로 쉽게 시작할 수 있습니다.
1
2
3
4
5
import pandas as pd
reviews = pd.read_csv("input_data/winemag-data-130k-v2.csv", index_col=0)
pd.set_option('max_rows', 5)
reviews
1
2
3
4
5
6
7
8
country ... winery
0 Italy ... Nicosia
1 Portugal ... Quinta dos Avidagos
... ... ... ...
129969 France ... Domaine Marcel Deiss
129970 France ... Domaine Schoffit
[129971 rows x 13 columns]
Python dictionary가 있으면 색인 ([]) 연산자를 사용하여 값에 액세스 할 수 있습니다. DataFrame의 열에 대해 동일한 작업을 수행 할 수 있습니다.
1
reviews['country']
1
2
3
4
5
6
0 Italy
1 Portugal
...
129969 France
129970 France
Name: country, Length: 129971, dtype: object
1
reviews['country'][0]
1
'Italy'
Indexing in pandas
Index-based selection Pandas 인덱싱에는 두 가지 패러다임이 있습니다. 첫 번째는 인덱스 기반 선택입니다. 데이터의 숫자 위치에 따라 데이터를 선택합니다. iloc은 이 패러다임을 따릅니다.
DataFrame에서 데이터의 첫 번째 행을 선택하려면 다음을 사용할 수 있습니다.
1
reviews.iloc[0]
1
2
3
4
5
6
country Italy
description Aromas include tropical fruit, broom, brimston...
...
variety White Blend
winery Nicosia
Name: 0, Length: 13, dtype: object
loc과 iloc은 모두 네이티브 파이썬과 반대로 행 우선, 열은 그 다음입니다. 이것은 행을 검색하는 것이 약간 더 쉽고 열을 검색하는 것이 약간 더 어렵다는 것을 의미합니다. 다음은 iloc으로 열을 검색하는 방법입니다.
1
reviews.iloc[:, 0]
1
2
3
4
5
6
0 Italy
1 Portugal
...
129969 France
129970 France
Name: country, Length: 129971, dtype: object
네이티브 파이썬에서 온 : 연산자는 “모든 것”을 의미합니다. 그러나 다른 선택기와 결합하면 값 범위를 나타내는 데 사용할 수 있습니다. 예를 들어 첫 번째, 두 번째 및 세 번째 행에서 country 열을 선택하려면 다음을 수행합니다.
1
reviews.iloc[:3, 0]
1
2
3
4
0 Italy
1 Portugal
2 US
Name: country, dtype: object
두 번째와 세 번째 항목만 선택하려면 다음을 수행합니다.
1
reviews.iloc[1:3, 0]
1
2
3
1 Portugal
2 US
Name: country, dtype: object
list로 전달할 수도 있습니다.
1
reviews.iloc[[0, 1, 2], 0]
1
2
3
4
0 Italy
1 Portugal
2 US
Name: country, dtype: object
마지막으로 음수를 선택에 사용할 수 있다는 사실을 아시면 좋습니다. 그러면 값의 끝부터 계산이 시작됩니다. 예를 들어 다음은 dataset의 마지막 5개 요소입니다.
1
reviews.iloc[-5:]
1
2
3
4
5
6
7
8
country ... winery
129966 Germany ... Dr. H. Thanisch (Erben Müller-Burggraef)
129967 US ... Citation
129968 France ... Domaine Gresser
129969 France ... Domaine Marcel Deiss
129970 France ... Domaine Schoffit
[5 rows x 13 columns]
Label-based selection 속성 선택을 위한 두 번째 패러다임은 loc 연산자(레이블 기반 선택)가 뒤 따르는 패러다임입니다. 이 패러다임에서 중요한 것은 위치가 아니라 데이터 인덱스 값입니다.
예를 들어 reviews에서 첫 번째 항목을 가져 오려면 이제 다음을 수행합니다.
1
reviews.loc[0, 'country']
1
'Italy'
iloc은 dataset의 인덱스를 무시하므로 개념적으로 loc보다 간단합니다. iloc을 사용할 때 우리는 dataset을 큰 행렬(2차원 리스트)처럼 취급합니다. 이 행렬은 위치별로 인덱싱해야합니다. 대조적으로 loc은 색인의 정보를 사용하여 작업을 수행합니다. dataset에는 일반적으로 의미있는 인덱스가 있으므로 일반적으로 loc을 사용하여 작업을 수행하는 것이 더 쉽습니다. 예를 들어 다음은 loc을 사용하는 것이 훨씬 더 쉬운 작업입니다.
1
reviews.loc[:, ['taster_name', 'taster_twitter_handle', 'points']]
1
2
3
4
5
6
7
8
taster_name taster_twitter_handle points
0 Kerin O’Keefe @kerinokeefe 87
1 Roger Voss @vossroger 87
... ... ... ...
129969 Roger Voss @vossroger 90
129970 Roger Voss @vossroger 90
[129971 rows x 3 columns]
loc과 iloc 중에 무엇을 사용해야할까? loc과 iloc는 방법이 약간 다른 인덱싱 체계를 사용합니다.
iloc은 범위의 첫 번째 요소가 포함되고 마지막 요소는 제외되는 Python stdlib 인덱싱 체계를 사용합니다. 따라서 0:10은 항목 0, …, 9를 선택합니다. 한편, loc은 포괄적으로 인덱스합니다. 따라서 0:10은 항목 0, …, 10을 선택합니다.
loc은 왜 이렇게 표현할까요? loc은 모든 stdlib 유형(예: str type)을 인덱싱 할 수 있습니다. 예를 들어 인덱스 값이 Apples, …, Potatoes, … 인 DataFrame이 있고 “Apples와 Potatoes 사이의 알파뱃 순서에 해당하는 모든 열을 선택하려면 df.loc[‘Apples’:’Potatoet](Python stdlib 인덱싱 체계를 사용한 경우)보다는 df.loc[‘Apples’:’Potatoes’]의 형태로 인덱싱하는 것이 훨씬 더 편리합니다.
DataFrame 인덱스가 간단한 숫자 목록인 경우 특히 혼란스럽습니다. 0, …, 1000. 이 경우 df.iloc [0 : 1000]은 1000 개의 항목을 반환하고 df.loc [0 : 1000]은 1001 개의 항목을 반환합니다! loc을 사용하여 1000 개의 요소를 얻으려면 하나를 낮추고 df.loc [0 : 999]를 요청해야합니다.
그렇지 않으면 loc 사용의 의미는 iloc의 의미와 동일합니다.
Manipulating the index
레이블 기반 선택은 인덱스의 레이블에서 힘을 얻습니다. 인덱스는 불변하지않습니다. 언제든 우리가 적절하다고 생각하는 방식으로 인덱스를 조작 할 수 있습니다. set_index() 메소드를 사용하여 작업을 수행 할 수 있습니다. title 필드에 set_index를 설정하면 다음과 같은 일이 발생합니다.
1
reviews.set_index("title")
1
2
3
4
5
6
7
8
9
country ... winery
title ...
Nicosia 2013 Vulkà Bianco (Etna) Italy ... Nicosia
Quinta dos Avidagos 2011 Avidagos Red (Douro) Portugal ... Quinta dos Avidagos
... ... ... ...
Domaine Marcel Deiss 2012 Pinot Gris (Alsace) France ... Domaine Marcel Deiss
Domaine Schoffit 2012 Lieu-dit Harth Cuvée Caro... France ... Domaine Schoffit
[129971 rows x 12 columns]
이것은 현재보다 더 나은 dataset에 대한 인덱스를 얻을 수 있는 경우 유용합니다.
Conditional selection
지금까지 우리는 DataFrame 자체의 구조적 속성을 사용하여 다양한 데이터를 인덱싱했습니다. 그러나 데이터로 흥미로운 일을하기 위해서는 종종 조건에 따라 질문을 해야합니다.
예를 들어 우리가 이탈리아에서 생산되는 평균 이상의 와인에 특별히 관심이 있다고 가정해 보겠습니다. 각 와인이 이탈리아산인지 아닌지 확인하는 것으로 시작할 수 있습니다.
1
reviews.country == 'Italy'
1
2
3
4
5
6
0 True
1 False
...
129969 False
129970 False
Name: country, Length: 129971, dtype: bool
이 작업은 각 record의 country를 기반으로 True/False boolean의 Series를 생성했습니다. 이 결과는 관련 데이터를 선택하기 위해 loc 내부에서 사용할 수 있습니다.
1
reviews.loc[reviews.country == 'Italy']
1
2
3
4
5
6
7
8
country ... winery
0 Italy ... Nicosia
6 Italy ... Terre di Giurfo
... ... ... ...
129961 Italy ... COS
129962 Italy ... Cusumano
[19540 rows x 13 columns]
이 DataFrame에는 약 20,000의 행이 있습니다. 원본은 약 130,000이었습니다. 이는 약 15%의 와인이 이탈리아에서 생산된다는 것을 의미합니다. 우리는 또한 어떤 것이 평균보다 나은지 알고 싶었습니다. 와인은 80~100점 척도로 검토되므로 최소 90점을 획득 한 와인을 의미 할 수 있습니다.
앰퍼샌드(&)를 사용하여 두 가지 질문을 결합 할 수 있습니다.
1
reviews.loc[(reviews.country == 'Italy') & (reviews.points >= 90)]
1
2
3
4
5
6
7
8
country ... winery
120 Italy ... Ceretto
130 Italy ... Ceretto
... ... ... ...
129961 Italy ... COS
129962 Italy ... Cusumano
[6648 rows x 13 columns]
Pandas에는 몇 가지 built-in conditional selector가 있으며, 그중 두 가지를 여기서 강조해보겠습니다. 첫 번째는 isin입니다. isin 사용하면 list에 있는 값을 선택할 수 있습니다. 예를 들어, 이탈리아 또는 프랑스에서만 와인을 선택하는 데 사용하는 방법은 다음과 같습니다.
1
reviews.loc[reviews.country.isin(['Italy', 'France'])]
1
2
3
4
5
6
7
8
country ... winery
0 Italy ... Nicosia
6 Italy ... Terre di Giurfo
... ... ... ...
129969 France ... Domaine Marcel Deiss
129970 France ... Domaine Schoffit
[41633 rows x 13 columns]
두 번째는 isnull (및 그 동반자 notnull)입니다. 이 메소드를 사용하면 비어 있거나(NaN) 비어 있지 않은 값을 선택 할 수 있습니다. 예를 들어 dataset에서 가격표가 없는 와인을 필터링하려면 다음을 수행합니다.
1
reviews.loc[reviews.price.notnull()]
1
2
3
4
5
6
7
8
country ... winery
1 Portugal ... Quinta dos Avidagos
2 US ... Rainstorm
... ... ... ...
129969 France ... Domaine Marcel Deiss
129970 France ... Domaine Schoffit
[120975 rows x 13 columns]
Assigning data
반대로 DataFrame에 데이터를 할당하는 것은 쉽습니다. 여러분은 상수 값을 지정할 수 있습니다.
1
2
reviews['critic'] = 'everyone'
reviews['critic']
1
2
3
4
5
6
0 everyone
1 everyone
...
129969 everyone
129970 everyone
Name: critic, Length: 129971, dtype: object
또는,
1
2
reviews['index_backwards'] = range(len(reviews), 0, -1)
reviews['index_backwards']
1
2
3
4
5
6
0 129971
1 129970
...
129969 2
129970 1
Name: index_backwards, Length: 129971, dtype: int64
Summary Functions and Maps
우리는 이제 DataFrame 또는 Series에서 관련 데이터를 선택하는 방법을 배웠습니다. 데이터 표현에서 올바른 데이터를 추출하는 것은 작업을 완료하는 데 중요합니다.
그러나 데이터가 항상 우리가 원하는 형식으로 메모리에서 나오는 것은 아닙니다. 때때로 우리는 당면한 작업에 맞게 다시 포맷하기 위해 더 많은 작업을 해야합니다. 이 튜토리얼에서는 “올바른” 입력을 얻기 위해 데이터에 적용 할 수 있는 다양한 작업을 다룹니다.
Summary functions
Pandas는 유용한 방식으로 데이터를 재구성하는 많은 간단한 “summary functions”(공식 이름은 아님)를 제공합니다. 예를 들어 describe() 메소드입니다.
1
reviews.points.describe()
1
2
3
4
5
6
count 129971.000000
mean 88.447138
...
75% 91.000000
max 100.000000
Name: points, Length: 8, dtype: float64
이 메소드는 주어진 열의 속성에 대한 높은 수준의 요약을 생성합니다. type을 인식하므로 입력의 데이터 유형에 따라 출력이 변경됩니다. 위의 출력은 숫자 데이터에만 의미가 있습니다. 문자열 데이터의 경우 다음과 같습니다.
1
reviews.taster_name.describe()
1
2
3
4
5
count 103727
unique 19
top Roger Voss
freq 25514
Name: taster_name, dtype: object
DataFrame 또는 Series의 열에 대한 특정 간단한 요약 통계를 얻으려면 일반적으로 도움이되는 pandas 함수가 있습니다. 예를 들어, 할당 된 점수의 평균(예: 평균 등급 와인의 점수)을 보려면 mean() 함수를 사용할 수 있습니다.
1
reviews.points.mean()
1
88.44713820775404
고유 값 목록을 보려면 unique() 함수를 사용할 수 있습니다.
1
reviews.taster_name.unique()
1
2
3
4
5
6
7
array(['Kerin O’Keefe', 'Roger Voss', 'Paul Gregutt',
'Alexander Peartree', 'Michael Schachner', 'Anna Lee C. Iijima',
'Virginie Boone', 'Matt Kettmann', nan, 'Sean P. Sullivan',
'Jim Gordon', 'Joe Czerwinski', 'Anne Krebiehl\xa0MW',
'Lauren Buzzeo', 'Mike DeSimone', 'Jeff Jenssen',
'Susan Kostrzewa', 'Carrie Dykes', 'Fiona Adams',
'Christina Pickard'], dtype=object)
고유 한 값 목록과 dataset에서 발생하는 빈도를 보려면 value_counts() 메소드를 사용할 수 있습니다.
1
reviews.taster_name.value_counts()
1
2
3
4
5
6
Roger Voss 25514
Michael Schachner 15134
...
Fiona Adams 27
Christina Pickard 6
Name: taster_name, Length: 19, dtype: int64
Maps
map은 하나의 값 집합을 가져 와서 다른 값 집합에 “매핑”하는 함수에 대해 수학에서 차용한 용어입니다. 데이터 과학에서 우리는 종종 기존 데이터에서 새로운 표현을 만들거나 현재의 형식에서 나중에 원하는 형식으로 데이터를 변환해야 할 필요가 있습니다. map은 이 작업을 처리하므로 작업을 완료하는 데 매우 중요합니다!
자주 사용할 두 가지 매핑 방법이 있습니다.
map()은 첫 번째 방법이며 약간 더 간단합니다. 예를 들어, 와인이 받은 점수를 평균값을 0으로 다시 계산하고 싶다고 가정합니다. 다음과 같이 할 수 있습니다.
1
2
review_points_mean = reviews.points.mean()
reviews.points.map(lambda p: p - review_points_mean)
1
2
3
4
5
6
0 -1.447138
1 -1.447138
...
129969 1.552862
129970 1.552862
Name: points, Length: 129971, dtype: float64
map()에 전달하는 함수는 Series에서 단일 값(위의 예에서 포인트 값)을 예상하고 해당 값의 변환 된 버전을 반환해야합니다. map()은 모든 값이 함수에 의해 변환 된 새로운 Series를 반환합니다. apply()는 각 행에서 사용자 정의 메소드를 호출하여 전체 DataFrame을 변환하려는 경우에 해당하는 메소드입니다.
1
2
3
4
5
def remean_points(row):
row.points = row.points - review_points_mean
return row
reviews.apply(remean_points, axis='columns')
axis=’index’로 reviews.apply()를 호출했다면 각 행을 변환하는 함수를 전달하는 대신 각 열을 변환하는 함수를 제공해야합니다. map() 및 apply()는 각각 새로운 변환 된 Series 및 DataFrame을 반환합니다. 호출 된 원본 데이터를 수정하지 않습니다. 리뷰의 첫 번째 행을 보면 원래 포인트 값이 여전히 있음을 알 수 있습니다.
1
reviews.head(1)

Pandas는 기본적으로 많은 일반적인 매핑 작업을 제공합니다. 예를 들어, 다음은 포인트 열을 다시 의미하는 더 빠른 방법입니다.
1
2
review_points_mean = reviews.points.mean()
reviews.points - review_points_mean
1
2
3
4
5
6
0 -1.447138
1 -1.447138
...
129969 1.552862
129970 1.552862
Name: points, Length: 129971, dtype: float64
이 코드에서 우리는 왼쪽에 있는 많은 값(Series의 모든 것)과 오른쪽에 있는 단일 값(평균값) 사이에서 연산을 수행합니다. Pandas는 이 표현식을 보고 dataset의 모든 값에서 해당 평균 값을 빼야한다는 것을 알아냅니다.
Pandas는 또한 동일한 길이의 Series간에 이러한 작업을 수행 할 경우 수행 할 작업을 이해합니다. 예를 들어 데이터 세트에서 국가 및 지역 정보를 쉽게 결합하는 방법은 다음을 수행하는 것입니다.
1
reviews.country + " - " + reviews.region_1
1
2
3
4
5
6
0 Italy - Etna
1 NaN
...
129969 France - Alsace
129970 France - Alsace
Length: 129971, dtype: object
이러한 연산자는 pandas에 내장 된 speed ups built를 사용하기 때문에 map() 또는 apply()보다 빠릅니다. 모든 표준 Python 연산자 (>, <, == 등)는 이러한 방식으로 작동합니다.
그러나 그것들은 덧셈과 뺄셈만으로는 할 수 없는 조건 논리를 적용하는 것과 같은 더 진보 된 일을 할 수 있는 map()이나 apply()만큼 유연하지 않습니다.
Grouping and Sorting
map을 사용하면 전체 열에 대해 DataFrame 또는 Series의 데이터를 한 번에 하나씩 변환 할 수 있습니다. 그러나 종종 우리는 데이터를 그룹화 한 다음 데이터가 속한 그룹에 특정한 작업을 수행합니다.
앞으로 배우게 될 것처럼 groupby() 연산으로 이를 수행합니다. 또한 데이터를 정렬하는 방법과 함께 DataFrame을 인덱싱하는 더 복잡한 방법과 같은 몇 가지 추가 주제를 다룰 것입니다.
Groupwise analysis
지금까지 많이 사용해온 함수 중 하나는 value_counts() 함수입니다. 다음을 수행하여 value_counts()가 하는 일을 복제 할 수 있습니다.
1
reviews.groupby('points').points.count()
1
2
3
4
5
6
7
points
80 397
81 692
...
99 33
100 19
Name: points, Length: 21, dtype: int64
groupby()는 주어진 와인에 동일한 점수 값을 할당하는 리뷰 그룹을 만들었습니다. 그런 다음 각 그룹에 대해 points 열을 잡고 몇 번 나타나는지 계산했습니다. value_counts()는 이 groupby() 작업의 숏컷입니다.
이 데이터에 이전에 사용한 요약 함수를 사용할 수 있습니다. 예를 들어, 각 포인트 값 범주에서 가장 저렴한 와인을 얻으려면 다음을 수행 할 수 있습니다.
1
reviews.groupby('points').price.min()
1
2
3
4
5
6
7
points
80 5.0
81 5.0
...
99 44.0
100 80.0
Name: price, Length: 21, dtype: float64
우리가 생성하는 각 그룹은 일치하는 값을 가진 데이터만 포함하는 DataFrame의 조각으로 생각할 수 있습니다. 이 DataFrame은 apply() 메소드를 사용하여 직접 액세스 할 수 있으며, 적합하다고 판단되는 방식으로 데이터를 조작 할 수 있습니다. 예를 들어 다음은 dataset의 각 winery에서 검토한 첫 번째 와인의 이름을 선택하는 한 가지 방법입니다.
1
reviews.groupby('winery').apply(lambda df: df.title.iloc[0])
1
2
3
4
5
6
7
winery
1+1=3 1+1=3 NV Rosé Sparkling (Cava)
10 Knots 10 Knots 2010 Viognier (Paso Robles)
...
àMaurice àMaurice 2013 Fred Estate Syrah (Walla Walla V...
Štoka Štoka 2009 Izbrani Teran (Kras)
Length: 16757, dtype: object
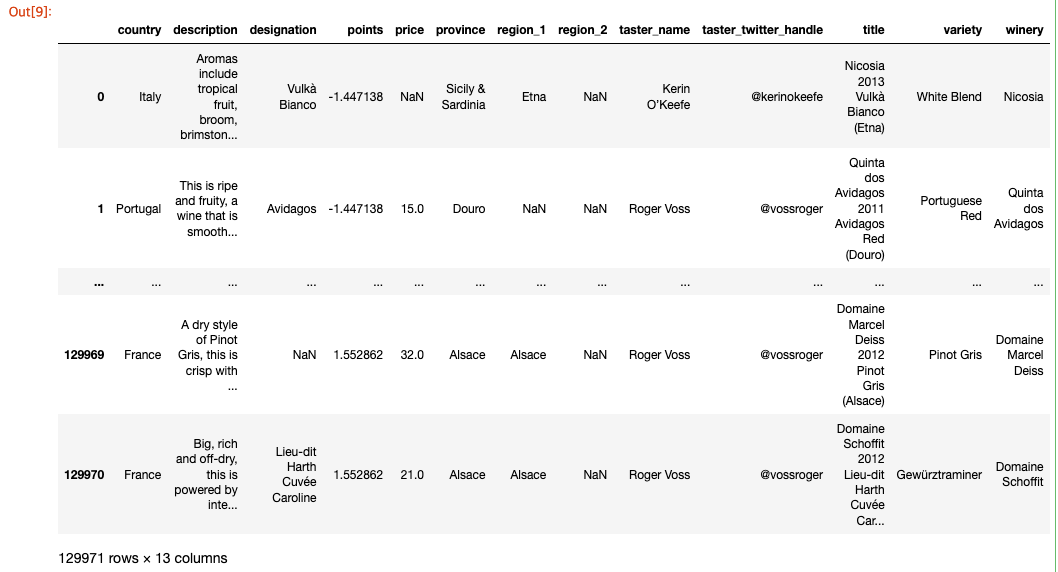
보다 세밀한 제어를 위해 둘 이상의 열을 기준으로 그룹화 할 수도 있습니다. 예를 들어, 국가 및 지방별로 최고의 와인을 고르는 방법은 다음과 같습니다. reviews.groupby([‘country’, ‘province’]).apply(lambda df: df.loc[df.points.idxmax()])
언급 할 가치가 있는 또 다른 groupby() 메소드는 agg()로, DataFrame에서 여러 기능을 동시에 실행할 수 있습니다. 예를 들어 다음과 같이 dataset의 간단한 통계 요약을 생성 할 수 있습니다.
1
reviews.groupby(['country']).price.agg([len, min, max])
1
2
3
4
5
6
7
8
9
len min max
country
Argentina 3800.0 4.0 230.0
Armenia 2.0 14.0 15.0
... ... ... ...
Ukraine 14.0 6.0 13.0
Uruguay 109.0 10.0 130.0
[43 rows x 3 columns]
groupby()를 효과적으로 사용하면 dataset으로 정말 강력한 일을 많이 할 수 있습니다.
Multi-indexes
지금까지 본 모든 예제에서 단일 레이블 인덱스가 있는 DataFrame 또는 Series 객체로 작업했습니다. groupby()는 우리가 실행하는 작업에 따라 때때로 다중 인덱스라고 불리는 결과를 낳는다는 점에서 약간 다릅니다.
다중 인덱스는 여러 수준이 있다는 점에서 일반 인덱스와 다릅니다.
1
2
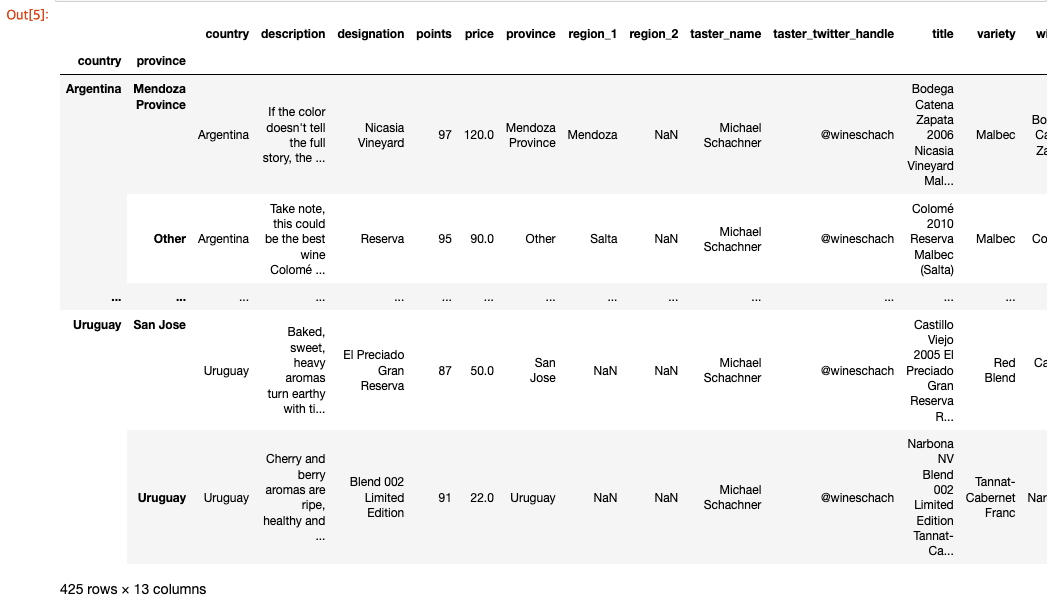
countries_reviewed = reviews.groupby(['country', 'province']).description.agg([len])
countries_reviewed
1
2
mi = countries_reviewed.index
type(mi)
1
pandas.core.indexes.multi.MultiIndex
다중 인덱스에는 단일 수준 인덱스에는 없는 계층 구조를 처리하는 여러 가지 방법이 있습니다. 또한 값을 검색하려면 두 가지 수준의 레이블이 필요합니다.
다중 인덱스의 사용 사례는 Pandas 문서의 MultiIndex/Advanced Selection 섹션에서 사용 지침과 함께 자세히 설명되어 있습니다.
그러나 일반적으로 가장 자주 사용하는 다중 인덱스 메소드는 일반 인덱스로 다시 변환하는 방법인 reset_index() 메소드입니다.
1
countries_reviewed.reset_index()

Sorting
countries_reviewed를 다시 살펴보면 그룹화가 값 순서가 아닌 인덱스 순서로 데이터를 반환한다는 것을 알 수 있습니다. 즉, groupby의 결과를 출력 할 때 행의 순서는 데이터가 아닌 인덱스의 값에 따라 달라집니다.
원하는 순서대로 데이터를 얻으려면 직접 정렬 할 수 있습니다. 이를 위해 sort_values() 메소드가 편리합니다.
1
2
countries_reviewed = countries_reviewed.reset_index()
countries_reviewed.sort_values(by='len')
1
2
3
4
5
6
7
8
country province len
179 Greece Muscat of Kefallonian 1
192 Greece Sterea Ellada 1
.. ... ... ...
415 US Washington 8639
392 US California 36247
[425 rows x 3 columns]
sort_values() 기본값은 오름차순 정렬이며 가장 낮은 값이 먼저 표시됩니다. 그러나 대부분의 경우 내림차순 정렬을 원합니다. 여기서 높은 숫자가 먼저 표시됩니다. 따라서 다음과 같이 진행됩니다.
1
countries_reviewed.sort_values(by='len', ascending=False)
1
2
3
4
5
6
7
8
country province len
392 US California 36247
415 US Washington 8639
.. ... ... ...
63 Chile Coelemu 1
149 Greece Beotia 1
[425 rows x 3 columns]
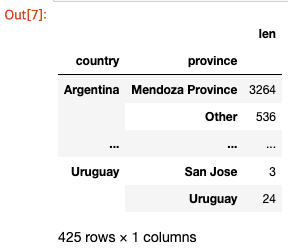
인덱스 값을 기준으로 정렬하려면 동반 메소드 sort_index()를 사용하십시오. 이 메소드는 sort_values()와 동일한 매개변수를 갖습니다.
1
countries_reviewed.sort_index()
1
2
3
4
5
6
country province len
0 Argentina Mendoza Province 3264
1 Argentina Other 536
.. ... ... ...
423 Uruguay San Jose 3
424 Uruguay Uruguay 24
마지막으로 한 번에 둘 이상의 열을 기준으로 정렬 할 수 있습니다.
1
countries_reviewed.sort_values(by=['country', 'len'])
1
2
3
4
5
6
7
8
country province len
1 Argentina Other 536
0 Argentina Mendoza Province 3264
.. ... ... ...
424 Uruguay Uruguay 24
419 Uruguay Canelones 43
[425 rows x 3 columns]
Data Types and Missing Values
DataFrame 또는 Series 내의 데이터 유형을 조사하는 방법을 알아봅시다.
Dtypes
DataFrame 또는 Series의 열에 대한 데이터 유형을 dtype이라고합니다.
dtype 속성을 사용하여 특정 열의 유형을 사용할 수 있습니다. 예를 들어 reviews DataFrame에서 price 열의 dtype을 찾을 수 있습니다.
1
reviews.price.dtype
1
dtype('float64')
dtypes 속성은 DataFrame에 있는 모든 열의 dtype을 반환합니다.
1
reviews.dtypes
1
2
3
4
5
6
country object
description object
...
variety object
winery object
Length: 13, dtype: object
Data types는 pandas가 내부적으로 데이터를 저장하는 방법에 대해 알려줍니다. float64는 64비트의 부동 소수점 숫자를 사용하고 있음을 의미합니다. int64는 float64와 비슷한 크기의 정수를 의미합니다.
염두에 두어야 할 한 가지 특징은 전적으로 문자열로 구성된 열이 자체 type을 갖지 않는다는 것입니다. 대신 object type이 제공됩니다.
astype() 함수를 사용하여 변환이 가능하다면 한 type의 열을 다른 type으로 변환 할 수 있습니다. 예를 들어 points 열을 기존 int64 data type에서 float64 data type으로 변환 할 수 있습니다.
1
reviews.points.astype('float64')
1
2
3
4
5
6
0 87.0
1 87.0
...
129969 90.0
129970 90.0
Name: points, Length: 129971, dtype: float64
DataFrame 또는 Series 인덱스에는 자체 dtype도 있습니다.
1
reviews.index.dtype
1
dtype('int64')
Pandas는 또한 범주형 데이터(categorical data) 및 시계열 데이터(timeseries data)와 같은 보다 이국적인 data type을 지원합니다. 이러한 data type은 거의 사용되지 않으므로 설명을 생략하겠습니다.
Missing data
결측값에는 “Not a Number”의 약자인 NaN 값이 제공됩니다. 기술적인 이유로 이러한 NaN 값은 항상 float64 dtype입니다.
Pandas는 결측값과 관련된 몇 가지 메소드를 제공합니다. NaN 항목을 선택하려면 pd.isnull()(또는 pd.notnull())을 사용할 수 있습니다. 다음과 같이 사용됩니다.
1
reviews[pd.isnull(reviews.country)]
1
2
3
4
5
6
7
8
country ... winery
913 NaN ... Gotsa Family Wines
3131 NaN ... Barton & Guestier
... ... ... ...
129590 NaN ... Büyülübağ
129900 NaN ... Psagot
[63 rows x 13 columns]
결측값 바꾸기는 일반적인 작업입니다. Pandas는 이 문제에 대해 정말 편리한 방법인 fillna()를 제공합니다. fillna()는 이러한 데이터를 완화하기 위한 몇 가지 다른 전략을 제공합니다. 예를 들어 각 NaN을 “Unknown”으로 간단히 바꿀 수 있습니다.
1
reviews.region_2.fillna("Unknown")
1
2
3
4
5
6
0 Unknown
1 Unknown
...
129969 Unknown
129970 Unknown
Name: region_2, Length: 129971, dtype: object
데이터베이스의 주어진 레코드 이후 언젠가 나타나는 첫 번째 null이 아닌 값으로 각 누락 된 값을 채울 수 있습니다. 이를 백필(backfill) 전략이라고합니다.
대체하려는 null이 아닌 값이 있을 수 있습니다. 예를 들어 이 dataset가 게시 된 후 reviewer ‘Kerin O’Keefe’가 Twitter handle을 @kerinokeefe에서 @kerino로 변경했다고 가정 해 보겠습니다. 이를 dataset에 반영하는 한 가지 방법은 replace() 메소드를 사용하는 것입니다.
1
reviews.taster_twitter_handle.replace("@kerinokeefe", "@kerino")
1
2
3
4
5
6
0 @kerino
1 @vossroger
...
129969 @vossroger
129970 @vossroger
Name: taster_twitter_handle, Length: 129971, dtype: object
replace() 메소드는 “Unknown”, “Undisclosed”, “Invalid”등과 같은 dataset에서 일종의 센티넬 값(sentinel value)이 제공되는 결측값을 대체하는 데 편리합니다.
Renaming and Combining
종종 데이터는 열 이름, 인덱스 이름 또는 우리에게 만족스럽지 못한 명명 규칙과 함께 우리에게 제공됩니다. 이 경우 pandas 함수를 사용하여 문제가되는 항목의 이름을 더 나은 이름으로 변경하는 방법을 배우게됩니다.
또한 여러 DataFrame이나 Series의 데이터를 결합하는 방법도 살펴 봅니다.
Renaming
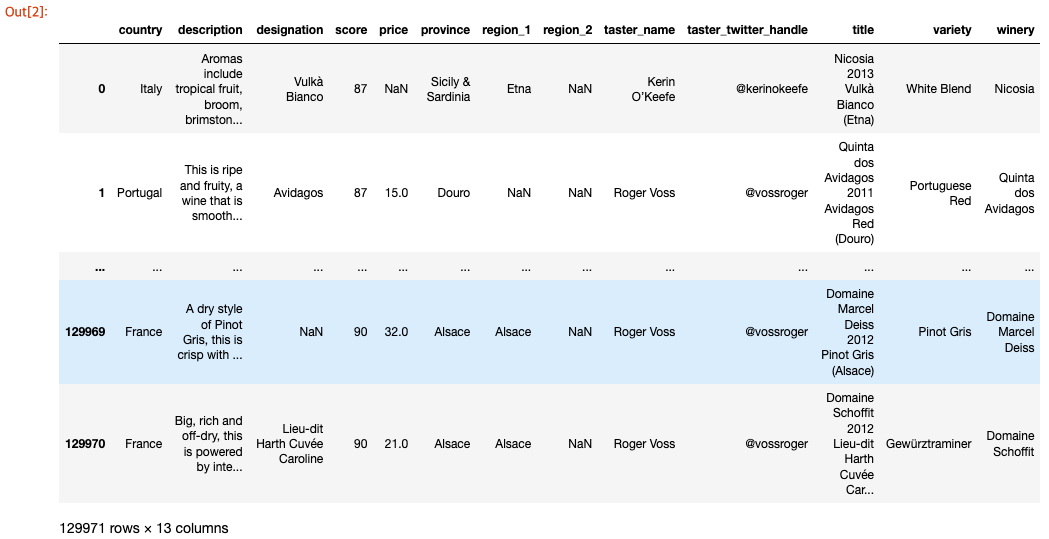
여기서 소개 할 첫 번째 함수는 rename()으로 인덱스 이름이나 열 이름을 변경할 수 있습니다. 예를 들어 dataset의 points 열을 score로 변경하려면 다음을 수행합니다.
1
reviews.rename(columns={'points': 'score'})
rename()을 사용하면 index 또는 column 키워드 매개 변수를 각각 지정하여 인덱스 또는 열 값의 이름을 바꿀 수 있습니다. 다양한 입력 형식을 지원하지만 일반적으로 Python dictionary가 가장 편리합니다. 다음은 인덱스의 일부 요소 이름을 바꾸는 데 사용하는 예입니다.
1
reviews.rename(index={0: 'firstEntry', 1: 'secondEntry'})
1
2
3
4
5
6
7
8
country ... winery
firstEntry Italy ... Nicosia
secondEntry Portugal ... Quinta dos Avidagos
... ... ... ...
129969 France ... Domaine Marcel Deiss
129970 France ... Domaine Schoffit
[129971 rows x 13 columns]
열 이름을 매우 자주 변경하지만 인덱스 값의 이름을 변경하는 경우는 거의 없습니다. 이를 위해 일반적으로 set_index()가 더 편리합니다.
행 인덱스와 열 인덱스는 모두 자기자신의 name 속성을 가질 수 있습니다. rename_axis() 메소드를 사용하여 이러한 이름을 변경할 수 있습니다.
1
reviews.rename_axis("wines", axis='rows').rename_axis("fields", axis='columns')
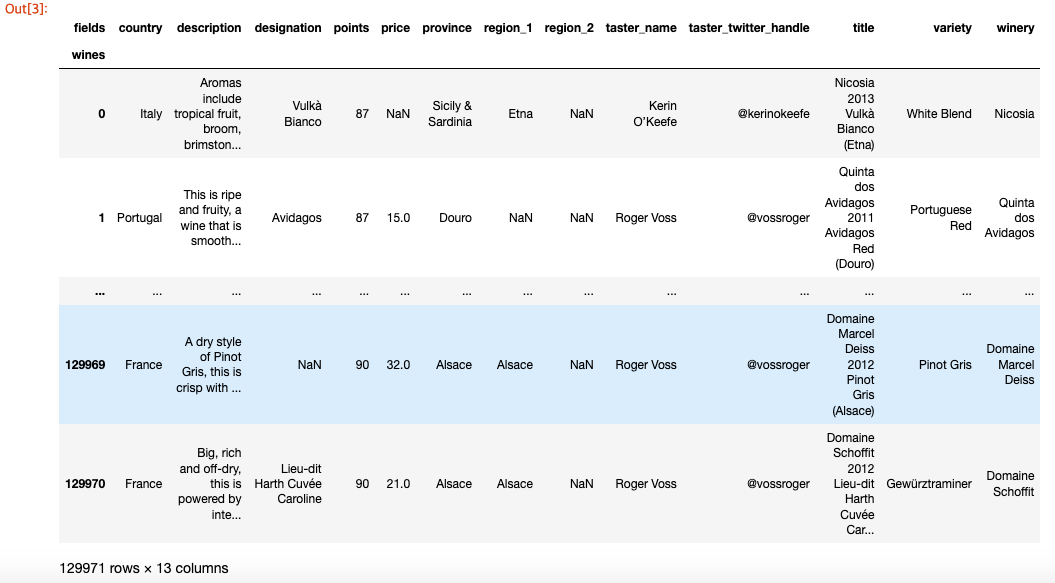
Combining
dataset에 대한 작업을 수행 할 때 때때로 다른 DataFrame이나 Series를 사소하지 않은 방법으로 결합해야합니다. Pandas에는 이를 위한 세 가지 핵심 방법이 있습니다. 사용하기 복잡한 순서대로 concat(), join() 및 merge()입니다. merge()가 할 수있는 대부분의 작업은 join()으로 더 간단하게 수행 할 수 있으므로 생략하고 여기에서 처음 두 함수에 초점을 맞출 것입니다.
가장 간단한 결합 방법은 concat()입니다. 요소들의 list가 주어지면 이 함수는 축을 따라 해당 요소를 함께 뭉칩니다.
이는 서로 다른 DataFrame이나 Series 개체에 데이터가 있지만 동일한 필드(열)가 있는 경우에 유용합니다. 한 가지 예시로, 원산지(이 예에서는 캐나다 및 영국)를 기준으로 데이터를 분할하는 YouTube 동영상 dataset입니다. concat()을 사용하여 두 국가를 하나로 묶을 수 있습니다.
1
2
3
4
canadian_youtube = pd.read_csv("input_data/CAvideos.csv")
british_youtube = pd.read_csv("input_data/GBvideos.csv")
pd.concat([canadian_youtube, british_youtube])
복잡성 측면에서 중간에 해당하는 결합기는 join()입니다. join()을 사용하면 인덱스가 공통인 여러 DataFrame 객체를 결합 할 수 있습니다. 예를 들어 캐나다와 영국에서 같은 날 유행했던 동영상을 가져오려면 다음을 수행 할 수 있습니다.
1
2
3
4
left = canadian_youtube.set_index(['title', 'trending_date'])
right = british_youtube.set_index(['title', 'trending_date'])
left.join(right, lsuffix='_CAN', rsuffix='_UK')
lsuffix 및 rsuffix 매개 변수는 데이터가 영국 및 캐나다 dataset에서 동일한 열 이름을 갖기 때문에 필요합니다. 만약 dataset에서 이미 열 이름을 선처리 했다면 이 매개변수를 사용할 필요는 없습니다.